Willkommen zu allesnurgecloud.com – Ausgabe #240
Puh, was für eine Hitze! Hier in Neuenstadt haben wir gerade um 21:44 am Freitagabend noch geschmeidige 27 Grad. Interessante Themen abseits meiner ausführlichen News in dieser Woche:
Eine neue Pew-Studie sagt: Nur 16 Prozent der Amerikaner glauben, dass KI der Gesellschaft guttut – während die Börse beim SpaceX-IPO jubelt und bald Anthropic und OpenAI folgen. Diese krasse Schere finde ich spannender als jede Bewertungsrunde.
In Texas hatte ein Farmer Land für symbolische 10 Dollar gespendet, das ein Park werden sollte – die Stadt hat es stattdessen für ein Rechenzentrum verkauft (10 Mio. für die Stadtkasse, 30 Mio. erwartete Steuern). Wirtschaftlich logisch, menschlich irgendwie auch bitter.
Positive News auf der Gegenseite: Craigslist-Gründer Craig Newmark hat rund eine halbe Milliarde verschenkt und will fast alles abgeben – und fürchtet ein Klima, in dem Großzügigkeit eher belächelt als bewundert wird.
Übrigens kannst Du meine Arbeit nun auf Patreon supporten, mir ein Bier ausgeben oder mal auf meiner Amazon-Wunschliste vorbeischauen – Danke! Falls du Interesse hast, im Newsletter oder Podcast Werbung zu buchen, kannst du das auf passionfroot machen oder mir einfach ne E-Mail als Antwort auf den NL schicken.
Und wie du schon weißt, baue ich aktuell mit Statuswerk eine komplett in Deutschland betriebene Statuspage – alle Daten, E-Mail und SMS bleiben hierzulande. Fokus nur darauf, dafür richtig und fair bepreist. Auf die Warteliste eintragen – Launch Ende Juni mit Early-Bird – hoffentlich kann ich das halten – hab schon fleissig Feature Wünsche von euch erhalten, gerne her damit!
So, und nun viel Spaß mit der neuen Ausgabe!
Happy Bootstrapping Podcast
In der aktuellen Podcast Folge 177 habe ich mit Jonas Scholz von Sliplane gesprochen. Mit Mitgründer Lukas Mauser baut er die European Container Cloud, auf der man Docker-Container per GitHub-Connect auf eigener Infrastruktur deployt. Wir reden über sein Marketing mit bewusst provokanten Blogposts wie „Stop using AWS“, den selbstgebauten Tech-Stack auf eigener Hardware und warum sie eine Cloud mit 1.100 Kunden komplett zu zweit und gebootstrappt betreiben. Gerne kannst du die Folge auf YouTube schauen oder wie immer bei Spotify, Apple und allen anderen Playern anhören.
Wenn dir die Podcastfolgen zu lang sind, kannst du gerne auch den Newsletter dazu abonnieren – erscheint jeden Montag (in der Regel).
allesnurgecloud.com ist ein kuratierter Newsletter mit Inhalten aus der Open-Source, Cloud und IT-Welt.
Für weiteren Content folge mir gerne auf Twitter, Mastodon oder LinkedIn.
Möchtest du den Newsletter wöchentlich per E-Mail erhalten?
Einfach hier abonnieren:
Hetzner standardisiert – und erhöht die Preise massiv
Keine zwei Monate nach der Frühjahrsrunde dreht Hetzner erneut an der Preisschraube, und diesmal deutlich heftiger. Seit dem 15. Juni gelten, wie heise berichtet und die Docs im Detail auflisten, neue Konditionen für Cloud- und dedizierte Server. Die geteilten vCPU-Linien (CAX, CX) bleiben mit rund 30–37 % im Rahmen der April-Anpassung. Die „Regular Performance“ CPX-Linie zieht massiv an, ein CPX42 in Deutschland steigt von 25,49 € auf 69,49 € (+173 %, netto), der CPX41 in den USA verdreifacht sich auf 120,49 €, ein Plus von 209 %. Auch die Dedicated-Cloud-Server der CCX-Linie legen durchweg über 100 % zu, ein CCX33 etwa von 62,49 € auf 138,49 €. Bestandskunden bleiben verschont, ein Rescale löst aber die neuen Preise aus.
Bei den dedizierten Servern verabschiedet sich Hetzner von individuellen Konfigurationen und standardisiert auf feste -1/-2/-3-Modelle. Dazu kommen happige Einrichtungsgebühren von bis zu 1.149 € – wer einen Top-Server bestellt, ist im ersten Monat schnell vierstellig dabei. Forum-User patrick7 formuliert das Kalkül trocken: Kunden mit niedrigen Gebühren locken und dann an der monatlichen Rate verdienen. „Der Freund jeder Firma, die Geld verdienen möchte, ist MRC, nicht OTC.“ enerspace urteilt sarkastischer: Hetzner positioniere sich nun „klar als Premium-Hoster – allerdings weiterhin mit Consumer-Hardware.“
Bemerkenswert ist, wie Hetzner kommuniziert. Nach Jahren meldet sich Geschäftsführer Martin Hetzner selbst im Forum, zunächst mit der etwas unglücklichen Aussage, die Preisstrategie sei „seit vielen Jahren unverändert“. Nach ein paar ungeschickten Antworten auf Kritik von Usern rudert er dann einen Tag später zurück: „Meine Kommunikation ist gestern leider nicht gut gelungen.“ Man gebe die ungewöhnliche Marktlage bewusst 1:1 weiter, wolle daran weder verdienen noch den Markt subventionieren; eine langfristige Vorankündigung bei gehaltenen Bestandspreisen hätte das Lager binnen Stunden leergefegt. Kurz darauf bedankt sich das Team für das konstruktive Feedback und stellt hilfreiche Optionen in Aussicht. Eine GF-Entschuldigung und ein ehrliches Dankeschön – das sieht man bei anderen Anbietern selten. Die Hardware-Mechanik dahinter hatte ich bei der Frühjahrsrunde beleuchtet.
Der Vertrauensschaden bleibt trotzdem. Im Hetzner Forum häufen sich Abschiede nach teils zwei Jahrzehnten Hetzner, dazu kaputte Preisseiten und drei Runden in einem halben Jahr. Wer trotzdem Hardware braucht: Ein Blick in die Serverbörse lohnt sich, dort gibt es ältere Modelle nach holländischem Auktionsprinzip oft spürbar günstiger.
Hetzner ist dabei nur der Anfang, wie auch ein heise-Video zur Preisrunde betont: Der KI-Boom frisst RAM- und Rechenzentrums-Kapazität, und das trifft die ganze Branche. Prompt kündigt nun auch Apple Preiserhöhungen an, Tim Cook nennt sie wegen der Speicherkrise „unvermeidlich“. Bleibt die Frage, wie die Hyperscaler reagieren. AWS, Azure und Google trifft die Welle genauso, nur können sie 100 bis 200 % schlecht über Nacht per Forum-Post durchdrücken – dort kommt die Verteuerung subtiler, über neue Generationen und Tarife. Hetzners Vorsprung als günstige europäische Alternative schrumpft damit zwar, den groben Hebel, an dem sie gerade ziehen, haben die Großen aber gar nicht.
Kräftige Preiserhöhung bei Hetzner: Cloud-Server teilweise dreimal so teuer
Souveränität als Wunsch, US-Cloud als Realität
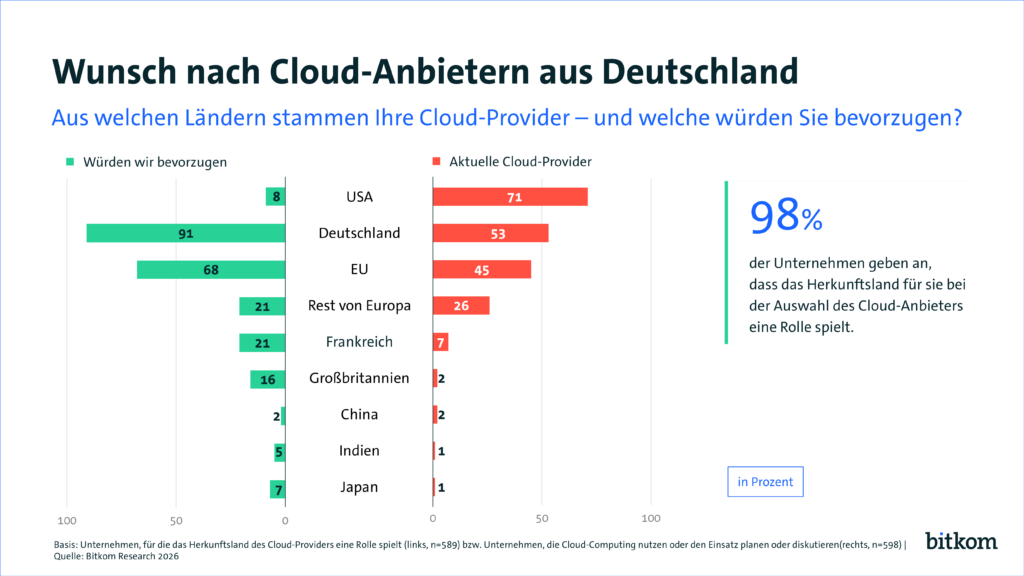
Der Wunsch nach digitaler Souveränität wächst – die Bereitschaft, dafür Abstriche zu machen, hinkt hinterher. So lässt sich der Cloud Report 2026 von Bitkom lesen, für den 603 Unternehmen ab 20 Beschäftigten befragt wurden. 85 % halten Deutschland für zu abhängig von US-Anbietern (Vorjahr 78 %), und 64 % fühlen sich durch die US-Politik – Stichwort CLOUD Act – gezwungen, ihre Cloud-Strategie zu überdenken, nach 50 % im Vorjahr.
Eindrücklich ist die Lücke zwischen Wunsch und Realität: 71 % beziehen heute aus den USA, bevorzugen würden das nur 8 %; deutsche Anbieter nutzen 53 %, wünschen sich aber 91 %. Der Haken steht direkt daneben: 43 % sagen, für ihre Anforderungen gebe es keine gleichwertige europäische Alternative zu den US-Hyperscalern.
Und beim Bezahlen wird’s zäh. Zwar wären inzwischen 37 % bereit, einen rein deutschen, vor ausländischem Zugriff geschützten Dienst auch mit Nachteilen zu nutzen (Vorjahr 27 %), aber nur 12 % würden 10-20 % mehr zahlen, und 58 % lehnen jeden Nachteil weiter ab. Größte Wechselbremse bleibt der Lock-in (59 %). Souveränität ist damit vor allem ein Bekenntnis – was Bitkom-Präsident Wintergerst selbst einräumt: Sie entstehe nicht durch Bekenntnisse, sondern durch verbindliche Standards und einen Staat, der vorangeht.
Dabei wird die Cloud ohnehin teurer: Bei 64 % stiegen die Betriebskosten 2025, für 2026 erwartet die Mehrheit erneut steigende Ausgaben – passend zum Hetzner-Beitrag oben. Treiber der Nachfrage ist klar die KI, deren Cloud-Nutzung von 42 auf 69 % in fünf Jahren springt (+27 pp, der größte Sprung), während reiner Speicherplatz stagniert und ERP sogar zurückgeht. Komplett in die Cloud will trotzdem kaum jemand: Private Cloud (64 %) liegt vor Public (53 %), viele fahren Multi- oder Hybrid-Cloud, und im Schnitt laufen erst 47 % der IT-Anwendungen aus der Cloud – in fünf Jahren sollen es 58 % sein.
Deutsche Cloud: 4 von 10 Unternehmen würden Abstriche in Kauf nehmen
Anzeige
We Manage & KRUU: Cloud für unter 0,5 % des Umsatzes

Gemeinsam mit unserem Kunden KRUU – dem nach eigenen Angaben weltweit größten mobilen Fotoboxvermieter – haben wir eine ausführliche Case Study veröffentlicht (PDF).
5.000 Fotoboxen in neun EU-Ländern und den USA, bis zu 800 Versendungen pro Tag in der Hochsaison, über 99,99 % Server-Uptime – und das alles bei IT-Kosten von unter 0,5 % des Jahresumsatzes (inkl. We Manage). Statt auf AWS zu setzen, was laut KRUU-Gründer Philipp Schreiber „Faktor 10 bis 20 teurer“ wäre, haben wir eine Multi-Provider-Architektur aus Gridscale, Hetzner und DigitalOcean aufgebaut, die saisonal mitatmet und wirtschaftlich bleibt.
Was mich an der Zusammenarbeit nach 10 Jahren besonders freut: Philipp und ich kennen uns noch aus dem Heilbronner Nachtleben – und die Philosophie hat sich nie geändert. Stabile Technologien. Kein Overengineering. Kein Overprovisioning.
Wenn du auch ein skalierbares Setup ohne Hyperscaler-Preise suchst – oder schlicht ein Backup für dein Ein-Personen-DevOps-Team brauchst, dann lass uns kurz sprechen.
Souveräne Google Deutschland-Cloud bis Ende 2026
Google Cloud hat auf seinem DACH-Summit den Fahrplan für seine souveräne Deutschland-Cloud vorgestellt – und der entscheidende Unterschied zu AWS steckt im Eigentümer. Betrieben wird die Plattform laut heise/iX von einer neuen, rechtlich und operativ von Google getrennten deutschen Gesellschaft, die Thales gehört und mit lokalem Personal besetzt ist. Root of Trust, Schlüssel, IP-Adressen, Identitäten und der gesamte Betrieb liegen bei Thales; Google soll keinen Zugriff auf Betrieb oder Daten haben. Das Modell entspricht dem von der Thales-Tochter S3NS in Frankreich betriebenen PREMI3NS, beide Regionen dienen sich gegenseitig als Ausweichstandort. Verfügbarkeit und Schlüsselübergabe sind für Ende 2026 geplant, bis dahin läuft eine Preview; Grundlage ist das neue BSI-Rahmenwerk C3A.
Genau hier trennt sich Google von AWS. Die AWS European Sovereign Cloud wird zwar über eine deutsche Holding mit drei GmbH-Töchtern, EU-Bürgern in der Leitung und ausschließlich EU-ansässigem Personal betrieben – gehört aber weiter Amazon. Die EU-Struktur ist eine Governance-Leitplanke, kein Eigentümerwechsel. Kritiker verweisen darauf, dass der CLOUD Act auf Daten in „possession, custody, or control“ eines US-Konzerns zielt und US-Eigentum damit trotz Frankfurt-HSMs und Verschlüsselung durchgreife. Googles Konstruktion schiebt mit Thales einen europäischen Eigentümer dazwischen; ob das in der Praxis hält, wird man sehen müssen.
Passend zum Bitkom-Report oben: Genau die fehlende Transparenz über Zugriffsrechte, die dort 87 % bemängeln, wollen beide Modelle adressieren – nur mit unterschiedlich tiefem Eigentümer-Schnitt. Google bietet drei Stufen (Data Boundary, das partnerbetriebene Dedicated, Air-Gapped) und beziffert seine Deutschland-Investitionen auf 5,5 Mrd. € bis 2029.
Google Cloud: Souveräne Cloud in Deutschland bis Ende 2026
IT Jobmarkt 2026: USA hui, Deutschland zäh
Der Tech-Arbeitsmarkt zieht 2026 wieder an – aber nicht überall. In seinem Deepdive zum Stand des Jobmarkts zeichnet Gergely Orosz (Pragmatic Engineer) mit Daten von TrueUp und Workforce.ai ein gespaltenes Bild: In den USA und UK steigen die Ausschreibungen für Softwareentwickler, Kanada stagniert, in Deutschland und Frankreich gehen sie zurück. US-Firmen stellen also wieder ein, vor allem zuhause, während europäische Häuser vorsichtiger bleiben – für die DACH-Leser eher gedämpft.
Spannender ist, wohin das Wachstum fließt. Die meisten Firmen priorisieren inzwischen AI Engineering vor klassischer Entwicklung; viele große Konzerne haben 50 bis 100 % mehr AI-Stellen ausgeschrieben als vor einem Jahr. Am schnellsten wächst Observability, weil AI-Agenten die Nachfrage durch die Decke treiben – Datadog ist der Profiteur, allein OpenAI soll dort 2025 rund 170 Mio. $ gelassen haben. Auch Security (Wiz) und Fintech (Ramp, Rippling) stellen rasant ein.
Bei den Großen ist das Bild gemischt: Apple +10 % und Google +5 % Entwickler-Headcount über zwei Jahre, Microsoft und Amazon leicht negativ. Meta erst Hiring-Rausch, dann 10 % Layoffs – Tausende Entwickler wurden vom Produkt aufs manuelle Daten-Labeling umgesetzt; Oracle kündigte im März bis zu 30.000 Stellen an. Der Markt wächst, aber selektiv und zunehmend KI-getrieben.
State of the software engineering job market in 2026
SeaweedFS auf Hetzner: S3 selbst betreiben
MinIO hat ja bekanntlich Lizenz und Funktionsumfang so weit eingedampft, dass es als S3 Speicher und in unserem Fall Backup-Ziel keinen Spaß mehr macht. Wir haben deshalb unsere komplette Backup-Infrastruktur – über 100 TB, 40+ Kundenbuckets, alle per restic – auf SeaweedFS umgezogen; ich habe das im Blog Schritt für Schritt aufgeschrieben. Der Anstoß kam von Stephan Hochdörfer – bei bitExpert haben sie mit SeaweedFS sehr gute Erfahrungen gemacht. Danke dafür!
SeaweedFS ist im Kern ein einziges Go-Binary mit vollwertiger S3-API. Darunter liegen Hetzner-Storage-Server mit vielen SATA-HDDs im Software-RAID 6 und XFS, optional mit 10G-Uplink – bei 100 TB Initial-Migration der Unterschied zwischen „über Nacht“ und „übers Wochenende“. Betrieb und Per-Bucket-Credentials laufen über eine eigene Ansible-Rolle unter MIT-Lizenz. Reicht ein Server nicht mehr, stellt man einfach einen zweiten daneben, und SeaweedFS verteilt die Volumes.
Die Migration lief bewusst phasenweise – erst die kleinen Kunden, dann die großen. Und nicht nur stumpf kopiert: pro Kunde haben wir das restic-Backup umgestellt, die Performance unter realer Last geprüft und vor jedem Endpoint-Switch ein byteweises rclone check gefahren. Wer 100 TB ohne Verify kopiert, hat kein Backup, sondern ein Versprechen. Die Georedundanz ist dann ein bewusst zeitversetzter rclone-Sync an einen zweiten Standort, damit ein fehlerhafter Nacht-Lauf nicht sofort auf den Replica durchschlägt.
Wirtschaftlich passt das zum Hetzner-Beitrag oben: Hetzner Object Storage kostet 7,72 € fürs erste TB und 10,35 € je weiterem (1 TB Traffic inklusive, interner EU-Traffic kostenlos). Bei 200 TB bist du fix vierstellig – ein eigener Storage-Server amortisiert sich dagegen oft in wenigen Monaten.
SeaweedFS auf Hetzner: S3-Storage selbst betreiben – von der Platte bis zur Kundenmigration
30 PB selbst gestackt: 40x günstiger als AWS
30 Petabyte für unter 500.000 $ statt 12 Millionen im Jahr bei AWS – so fasst Standard Intelligence den Bau seines Storage-Clusters „the heap“ in Downtown San Francisco zusammen. Das Lab trainiert Modelle auf 90 Millionen Stunden Videodaten, und Video braucht grob das 500-Fache des Speichers eines Text-LLMs. Statt AWS‘ 1,13 Mio. $/Monat (mit Egress) landet der Eigenbau bei 29.500 $/Monat inklusive Abschreibung – rund 38x günstiger, gegenüber Cloudflare R2 noch 10x. Pro Terabyte: 1 $ statt 38 $.
Möglich macht das vor allem ein bewusster Verzicht: Trainingsdaten sind ein Commodity, ein verlorenes Prozent tut kaum weh. Es braucht also keine 13 Neunen Verfügbarkeit, zwei reichen – und damit fällt der ganze Redundanz- und Sharding-Apparat weg. Die Software sind 200 Zeilen Rust fürs Schreiben, nginx fürs Lesen, SQLite für Metadaten, alles auf XFS. Ceph und MinIO haben sie bewusst nicht genommen, ein 200-Zeilen-Programm debuggt sich schlicht leichter. Die Hardware: 2.400 gebrauchte Enterprise-HDDs in 100 NetApp-DS4246-JBODs plus zehn eBay-Head-Nodes, verschraubt in einer 36-Stunden-Party (ihr Wortwitz: „S3″ – Storage Stacking Saturday).
Die Lehre bleibt: Storage wird massiv über Kosten verkauft, und ab einer gewissen Größe rechnet sich Eigenbau – selbst das Internet Archive war laut SI mit AWS-Friends-&-Family-Rabatt noch zehnmal teurer als eigene Racks. Übertragbar ist das aber nur mit passenden Anforderungen: Wer Kundendaten mit echten Verfügbarkeits- und Durabilitätsgarantien hält, kann den Redundanz-Apparat eben nicht weglassen.
How to Rack 30 Petabytes of Storage
curl macht Urlaub – von Security-Reports
curl legt im Juli eine Pause ein – und zwar von Security-Reports. Wie Maintainer Daniel Stenberg im Blog ankündigt, nimmt das Projekt zwischen dem 1. Juli und 3. August keine Schwachstellenmeldungen mehr an: Das HackerOne-Formular pausiert, die Security-Mailadresse wird zur Sackgasse. „Summer of Bliss“ nennt er das.
Interessant ist der Grund, denn der hat sich verschoben. Die AI-Slop-Welle, die curls Bug-Bounty-Programm 2025 lahmlegte, ist seit der Rückkehr zu HackerOne im März weitgehend vorbei. Die KI-gestützten Reports sind inzwischen richtig gut: Die Bestätigungsquote liegt wieder bei 15-16 % wie vor dem KI-Zeitalter, die Meldungsrate ist mit grob dem Doppelten des Vorjahres aber so hoch wie nie. Das Problem ist also nicht mehr Müll, sondern schiere Masse – und jede valide Meldung braucht weiter einen Menschen, der sie nachstellt, fixt und koordiniert. curl sind dafür rund sieben Leute.
Das ist die eigentliche Geschichte: eine Bibliothek in zig Milliarden Geräten, getragen von einer Handvoll Maintainer und sehr wenigen Sponsoren. Zahlende Support-Kunden werden auch im Juli bedient – ein dezenter Hinweis an alle, die curl produktiv nutzen. Dass KI durchaus echte Lücken findet, zeigte im Mai ein Mythos-Modell, das eine reale curl-Schwachstelle aufspürte. Stenbergs Haltung bleibt trotzdem klar: „The bad guys won’t rest. But we will.“
Reliability Debt: die Rechnung kommt um 3 Uhr
Kein Incident seit Monaten heißt nicht, dass dein Setup resilient ist – es heißt nur, dass der nächste noch kommt. Auf diese unbequeme Wahrheit laufen zwei lesenswerte SRE-Texte hinaus. Joe McKevitt, CTO von Uptime Labs, trennt sauber zwischen Prävention und Vorbereitung: Code-Reviews, Release-Gates, Testabdeckung sind richtig, beruhen aber auf der Annahme, ein System ließe sich fehlerfrei machen – in verteilten Systemen unter echter Last hält die nicht. Wer nur vorbeugt, steht im Ernstfall nicht vor dem technischen Problem, sondern vor dem Chaos drumherum: falsche Leute, abreißende Kommunikation, verlorene Zeit vor dem eigentlichen Fix.
Spiros Economakis liefert den passenden Begriff dazu: Reliability Debt. Wie Tech Debt, nur leiser – der fehlende Alert, die vertagte Retry-Logik, das übersprungene Incident-Review. Im Normalbetrieb unsichtbar, fällig wird sie unter Last, am liebsten um 3:12 Uhr am Sonntag. Seinen Punkt zur Alert-Müdigkeit kenne ich aus dem eigenen Betrieb gut: Wir ignorieren Risiken nicht aus Gleichgültigkeit, sondern weil zu viele Fehlalarme das Vertrauen in die Signale zerstören. Ein Alert, der nicht klar auf Userwirkung zeigt, wird irgendwann weggeklickt – und das „beobachten wir in Prod“ sagt sich schnell. Wer den Alerts aber nicht mehr traut, handelt nicht mehr.
Beide enden bei derselben Haltung, auch zur KI: Sie kann Muster über Incidents hinweg erkennen, Runbooks generieren, Logs zusammenfassen – priorisieren, entscheiden und unter Druck den Überblick behalten muss aber weiter ein Mensch. „Hope is not a strategy“ bleibt der Kern.
Und wenn man zu lange nicht reagiert, fliegt es einem im unpassendsten Moment um die Ohren.
Incidents *Will* Happen. Are You (Actually) Prepared?
Ryzen AI Halo: Viel Speicher, schmale Bandbreite
AMD schiebt mit dem Ryzen AI Halo eine x86-Antwort auf Nvidias DGX Spark nach, wie PC Games Hardware berichtet. Der Mini-PC auf Basis des Ryzen AI Max+ 395 („Strix Halo“) ist seit Kurzem vorbestellbar, vorerst nur über Micro Center in den USA, für 3.999 $, Auslieferung ab dem 10. Juli. Gegenüber der ARM-basierten DGX Spark, die im Februar von 3.999 auf 4.699 $ kletterte, bleibt AMD bei x86 und ROCm; der Halo lässt sich damit auch ganz banal als Windows- oder Linux-Rechner nutzen.
Spannend ist der Speicher: 128 GiB LPDDR5X-8000 dienen CPU, GPU und NPU gemeinsam als Unified Memory, bis zu 96 GiB davon lassen sich als VRAM deklarieren. AMD verspricht, damit Modelle „bis zu 200 Milliarden Parameter“ lokal auszuführen, was aber nur mit aggressiver Quantisierung aufgeht: In Q4 passt ein 200B-Modell in rund 100 GB, in FP16 ist schon bei rund 50–60B Schluss. Der eigentliche Flaschenhals ist die Bandbreite. Die 256-Bit-Anbindung liefert nur etwa 256 GB/s (gemessen eher 215) – ein Bruchteil der über 1 TB/s einer dedizierten GPU. Viel Kapazität, mäßiger Durchsatz: Große Modelle laden, generieren aber zäh, ein 70B-Modell in BF16 kommt auf grob 14 Tokens/s.
Dass der EU-Preis über der reinen Dollar-Umrechnung liegen dürfte, liegt an den angespannten Speicherpreisen – dasselbe RAM-Thema, das oben schon Hetzner zur dritten Preisrunde getrieben hat (allesnurgecloud.com/ausgabe-225). Im dritten Quartal folgt mit dem Ryzen AI Max+ 495 („Gorgon Halo“) eine Variante mit 192 GiB und 160 GiB VRAM, dann auch über Asus, HP und Lenovo.
Ryzen AI Halo: AMDs x86-Antwort auf Nvidia DGX Spark ist da
Gemma 4 auf einem 2016er Xeon – ohne GPU
Dass man für lokale KI keine 4.000-Euro-Kiste braucht, zeigt Christina Sørensen (eza-Autorin, im NixOS Steering Committee) in einem dreiteiligen Blogpost. Sie quetscht ein 26-Milliarden-Parameter-MoE – Gemma 4 26B-A4B, 128 Experten, davon 8 aktiv pro Token, macht rund 3,8B aktive Parameter – auf einen ausgemusterten Intel Xeon E5-2620 v4 von 2016. Acht Kerne, kein AVX-512, keine GPU, dafür 128 GB lahmes DDR3. Und das Ding läuft, in Q8, mit Lesegeschwindigkeit. Da musste ich kurz schmunzeln.
Der Haken: ollama oder Standard-llama.cpp kannst du dafür vergessen. Sørensen nimmt den Fork ik_llama.cpp und dreht an 25 Flags, von denen die Hälfte undokumentiert ist und ein Viertel still scheitert – Speculative Decoding, MoE-Routing entlang der CPU-Caches, ein per --mlock gegen Swap gepinntes Modell, Flash Attention über handgeschriebene CPU-Kernel. Klingt nach Bastelei, ist aber sauber begründet. Der Footprint liegt bei 82 GB, und das Kuriose dabei: Der KV-Cache ist bei 262K Kontext mit 56 GB größer als das Modell selbst, das nur 25 GB wiegt.
Was bei mir hängenbleibt, passt zum Ryzen-AI-Halo-Beitrag oben: Limitierend ist beim Generieren nicht die Rechenleistung, sondern die Speicherbandbreite – die „memory wall“, egal ob Schrott-Xeon oder H100. Und genau diese Stellschrauben versteckt dir jedes Black-Box-Tool. Sørensens eigentliche Pointe steht schon im Titel ihres ersten Posts: Ein hochgeladener Gewichts-Dump ist eben noch lange kein „Open Source“. Während Kimi K2.6 (allesnurgecloud.com/ausgabe-233) noch ein ganzes Rechenzentrum brauchte, reicht hier ein zehn Jahre alter Server im Keller – wenn man die Engine wirklich versteht. Für Homelab-Leute ein Pflichttermin.
A 10 year old Xeon is all you need
Schmunzelecke
Ein Tower Defense Game, bei dem man „nebenher“ Cloud Architektur lernt? Was gibt es Besseres? (Projekt bei GitHub).
Wer kennt es nicht, die Apple Music App startet auf dem Mac, weil man den Kopfhörer aufsetzt oder aus Versehen auf Play kommt? Da hilft „Music Decoy“ – Open Source – „As long as the Music Decoy app is running, the system Music app won’t launch when you accidentally press“.
💡 Link Tipps aus der Open Source Welt
Jarvis – Interaktives Web Frontend für Prometheus Alertmanager
Jarvis ist ein self-hosted Web Frontend für Prometheus Alertmanager, das über reine Dashboard-Funktionalität hinausgeht – gebaut für Teams, die auf Alerts reagieren müssen, nicht nur beobachten.
Key Features:
- Echtzeit via WebSocket: Alerts aktualisieren sich live, kein Page Reload nötig
- Persistente Historie: Kompletter Alert Lifecycle in SQLite oder PostgreSQL – überlebt Container-Restarts und Alertmanager-Reconnects
- Claiming: Alerts sich selbst zuweisen, damit das Team sieht, wer sich darum kümmert
- Kommentare: Fingerprint-gebundene Notizen, die Re-Fires überleben – ideal für Incident-Dokumentation
- Silence Management: Erstellen, editieren, verlängern, löschen direkt aus dem UI mit Live-Preview der betroffenen Alerts
- Expiring Silence Warning: Alerts mit Silence < 15 Minuten werden automatisch als aktiv eingestuft – verhindert Überraschungs-Pages um 3 Uhr morgens
- Multi-Cluster: Mehrere Alertmanager-Instanzen gleichzeitig pollen
- Label Filter: Matcher-Chips (= != =~ !~) mit URL-Serialisierung zum Teilen gefilterter Views
- AI Prompt: Generiert einen SRE-Prompt mit vollem Alert-Kontext zum Einfügen in Claude/ChatGPT – lokal gebaut, keine Netzwerk-Calls
- Auth: Drei Modi – offen, internes User Management, OIDC (Keycloak, Authentik, Dex)
- Single Binary: Go Backend embeddet den Vite Build, ein Container reicht
Deployment via Docker/Podman Compose oder Helm Chart. Card und List View, Dark/Light Theme, Full-Text Search.
Tech Stack: Go 1.25, React 19, TypeScript, Tailwind CSS v4, Zustand, distroless Container.
Noch ganz frisch (v1.3.1, Solo-Entwickler), aber funktional bereits bemerkenswert ausgereift. Wer Karma nutzt und sich persistente Historie, Claiming und besseres Silence Management wünscht, sollte Jarvis ausprobieren – die Expiring-Silence-Warnung allein ist das Setup wert.
https://github.com/kj187/jarvis
ReClip – Self-Hosted Video & Audio Downloader mit Web UI
ReClip ist ein minimalistischer, self-hosted Video- und Audio-Downloader mit Web-Oberfläche. URLs von YouTube, TikTok, Instagram, Twitter/X und 1000+ weiteren Seiten einfügen, Format und Qualität wählen, herunterladen – fertig.
Key Features:
- 1000+ Seiten: Alles was yt-dlp unterstützt – YouTube, TikTok, Instagram, Twitter/X, Reddit, Vimeo, SoundCloud, Loom und viele mehr
- MP4 oder MP3: Video-Download oder Audio-Extraktion mit Quality/Resolution Picker
- Bulk Downloads: Mehrere URLs auf einmal einfügen, automatische Deduplizierung
- Minimalistisch: ~150 Zeilen Python Backend (Flask), Vanilla HTML/CSS/JS Frontend ohne Build-Step, nur 2 Dependencies (Flask + yt-dlp)
Benötigt yt-dlp und ffmpeg. Deployment via ./reclip.sh oder Docker.
Angenehm unkompliziert – wer einen yt-dlp Wrapper mit hübschem UI für den Heimserver sucht, ist in 2 Minuten fertig. Die Codebasis ist so klein, dass man sie komplett überblicken und nach Belieben anpassen kann.
https://github.com/averygan/reclip
❓ Feedback & Newsletter Abo
Vielen Dank, dass du es bis hierhin geschafft hast!
Kommentiere gerne oder schicke mir Inhalte, die du passend findest.
Falls dir die Inhalte gefallen haben, kannst du mir gerne auf Twitter folgen.
Gerne kannst du mir ein Bier ausgeben oder mal auf meiner Wunschliste vorbeischauen – Danke!
Möchtest du den Newsletter wöchentlich per E-Mail erhalten?
Einfach hier abonnieren: