Willkommen zu allesnurgecloud.com – Ausgabe #241
Tja, was für eine „heiße“ Woche im wahrsten Sinne des Wortes. Claude Fable geht bis jetzt nicht wieder, dafür holen die Open-Source-Modelle spürbar auf und der Abstand wird kleiner – dazu habe ich ein paar News am Ende des Newsletters zu den neuen Kimi und GLM Modellen.
Ansonsten scheint KI für uns noch immer zu billig zu sein. In einer Analyse hat man nun Folgendes herausgefunden:
For $200 A Month, You Can Burn $8000 in Anthropic Tokens or $14,000 In OpenAI Tokens
Tja, damit muss meine Claude Subscription wohl in Zukunft deutlich teurer werden, damit sich das rechnet. Die Rufe nach dem Platzen der Blase werden immer lauter. Und bei uns fällt halt einfach mal das GSM-R Netz der Bahn aus – und die Störung sorgte für landesweite Verspätungen und Zugausfälle.
Und wie du schon weißt, baue ich aktuell mit Statuswerk eine komplett in Deutschland betriebene Statuspage als Alternative zur Atlassian Statuspage – alle Daten, E-Mail und SMS bleiben hierzulande. Fokus nur darauf, dafür richtig und fair bepreist. Auf die Warteliste eintragen – Launch im Juli mit Early-Bird.
So, und nun viel Spaß mit der neuen Ausgabe
Happy Bootstrapping Podcast
In der aktuellen Podcast Folge 178 habe ich mit Marvin Behrendt von Feedbackdoktor gesprochen. Als Coach, Trainer und Autor hat er sein Buch „Feedback sicher geben und nehmen“ bewusst im Self-Publishing herausgebracht – und dafür sogar einen fertigen Verlagsvertrag abgelehnt. Wir reden über sein Geschäftsmodell als Solopreneur, Akquise über LinkedIn als Social-Selling-Funnel und seine Pläne für eine KI-App als Personalabteilung für Unternehmen ohne Personalabteilung. Gerne kannst du die Folge auf YouTube schauen oder wie immer bei Spotify, Apple und allen anderen Playern anhören.
Wenn dir die Podcastfolgen zu lang sind, kannst du gerne auch den Newsletter dazu abonnieren – erscheint jeden Montag (in der Regel).
Support the Newsletter
Übrigens kannst Du meine Arbeit nun auf Patreon supporten, mir ein Bier ausgeben oder mal auf meiner Amazon-Wunschliste vorbeischauen – Danke! Falls du Interesse hast, im Newsletter oder Podcast Werbung zu buchen, kannst du das auf passionfroot machen oder mir einfach ne E-Mail als Antwort auf den NL schicken.
Auf allesnurgecloud.com findest Du vorherige Ausgaben und den RSS-Feed.
Vielen Dank für Dein Interesse und wie immer freue ich mich über Feedback und Weiterempfehlungen.
allesnurgecloud.com ist ein kuratierter Newsletter mit Inhalten aus der Open-Source, Cloud und IT-Welt.
Für weiteren Content folge mir gerne auf Twitter, Mastodon oder LinkedIn.
Möchtest du den Newsletter wöchentlich per E-Mail erhalten?
Einfach hier abonnieren:
Preiserhöhungen auch bei OVH
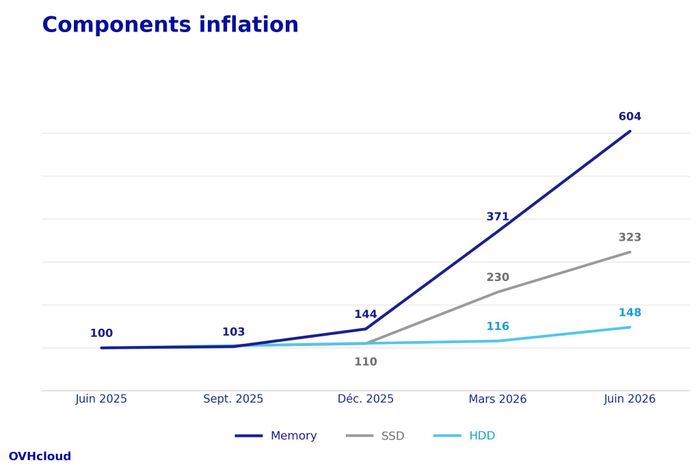
Während die KI-Branche GPUs hortet, zahlt der Rest der Branche die Rechnung. Octave Klaba, Gründer von OVHcloud, macht auf X die Kollateralschäden mit Zahlen greifbar: Die drei verbliebenen RAM-Hersteller haben ihre Fabriken auf das margenstarke HBM für KI-Beschleuniger umgestellt, auf Kosten von Standard-RAM (DDR4/DDR5).
Die Folge ist eine Preisspirale, die Klaba ungewöhnlich offen durchrechnet:
- RAM: im Juni 2026 das Sechsfache von Juni 2025, prognostiziert das Neunfache im September, das Zwölffache Anfang 2027.
- NVMe-SSDs ×7, HDDs ×3,5 im selben 16-Monats-Zeitraum.
- Chips und damit CPUs, Mainboards, Netzwerkkarten: angekündigte +15 bis 20 % — vorerst.
OVH zieht daraus die übliche Konsequenz: Bestandskunden und Neubestellungen werden Ende August teurer, allerdings nur in den jeweils zwei jüngsten Generationen je Reihe (etwa Advance Gen4 und Gen3). Ältere Linien wie Kimsufi oder Rise bleiben verschont. Wer seine aktuellen Preise halten will, kann 12, 24 oder 48 Monate im Voraus zahlen und den Preis so festschreiben, ein Detail, das in der allgemeinen Aufregung untergeht.
Bemerkenswert ist weniger die Erhöhung selbst als ihre Inszenierung. Klaba hatte das Szenario schon im Februar angekündigt, es trat ein, und nun warnt er erneut, die Lage sei außergewöhnlich und halte bis 2028 an. Das passt nahtlos zur Hetzner-Preisrunde aus Ausgabe 240 — der KI-bedingte Hardware-Hunger schlägt mittlerweile flächendeckend bis zu den europäischen Hostern durch. Günstig bleibt vieles davon trotzdem; die Frage ist eher, ob man überhaupt noch beliefert wird.
Bei Apple gehen die Preise nun übrigens auch rauf bzw. wurden angepasst, das schickte die Aktie erst mal ein wenig auf Talfahrt. Ich würde sagen es sind eigentlich überall mindestens 10%, egal ob Macbook Neo oder Pro – 10 % geht es mindestens rauf.
Twitter Beitrag OVH CEO Oktave Klaba
Layoffs bei Elastic mit KI als Begründung
7 Prozent der Belegschaft, weltweit: Elastic-CEO Ash Kulkarni hat den Stellenabbau im Firmenblog verkündet, verpackt in die inzwischen vertraute Sprache. Die Kürzung sei „ein Zeichen von Zuversicht, kein Rückzug“, die Gesamtbelegschaft werde im laufenden Geschäftsjahr trotzdem wachsen. Begründet wird der Umbau mit KI und Automatisierung, die schlankere Teams ermöglichten; das Engineering wird auf drei Bereiche unter je einem direkt an den CEO berichtenden Leiter zusammengezogen.
Dass „leaner operieren“ und „Headcount wächst trotzdem“ im selben Schreiben stehen, ist der übliche Spagat solcher Ankündigungen. Wer wirklich geht und wer kommt, steht eben in unterschiedlichen Spalten.
Interessanter als das US-Wording ist die Umsetzung in Deutschland, wo ein Großteil der Elastic-Belegschaft im Engineering sitzen soll. Anders als in Ländern, in denen Accounts schlicht abgeschaltet worden sein sollen, erhielten Betroffene hierzulande über den Betriebsrat zunächst ein Angebot für einen Aufhebungsvertrag und könnten nachverhandeln. Was bei einem Scheitern passiere, sei bislang offen — eine reguläre Kündigung dürfte vor dem Arbeitsgericht ohnehin schwer zu begründen sein.
Der Betriebsrat kümmere sich derzeit vor allem um Informationsparität, damit gerade die vielen Expats ihre Rechte kennen, bevor sie ein Angebot unterschreiben. Ob KI tatsächlich der Treiber ist oder nur die bequeme Begründung, lässt sich von außen nicht beurteilen.
Ein Gesicht bekam der Abbau durch Brian Curtin, sieben Jahre Principal Engineer und zuletzt Tech Lead, der seinen Rauswurf öffentlich auf LinkedIn schildert. Es traf ihn mitten in einem Team-Meeting: Erst verschwand der Zugriff auf das, was er gerade teilte, dann erfuhr er live, dass es das war. Da der verlorene Zoom-Zugang das laufende Meeting nicht beendete, machte sein Team daraus einen fast zweistündigen Abschied; „it was better to cry with them“, schreibt Curtin. Aufgebaut hatte er unter anderem Elastics GCP-Marketplace-Anbindung und große Teile der Billing-Systeme; jetzt sucht er etwas Neues.
Hier scheint es eine Lücke zwischen Ankündigung und der Lage in den Teams zu geben, aber das ist ja leider nichts neues.
CEO Ash Kulkarni’s organizational announcement to Elastic employees
Anzeige
We Manage & KRUU: Cloud für unter 0,5 % des Umsatzes

Gemeinsam mit unserem Kunden KRUU – dem nach eigenen Angaben weltweit größten mobilen Fotoboxvermieter – haben wir eine ausführliche Case Study veröffentlicht (PDF).
5.000 Fotoboxen in neun EU-Ländern und den USA, bis zu 800 Versendungen pro Tag in der Hochsaison, über 99,99 % Server-Uptime – und das alles bei IT-Kosten von unter 0,5 % des Jahresumsatzes (inkl. We Manage). Statt auf AWS zu setzen, was laut KRUU-Gründer Philipp Schreiber „Faktor 10 bis 20 teurer“ wäre, haben wir eine Multi-Provider-Architektur aus Gridscale, Hetzner und DigitalOcean aufgebaut, die saisonal mitatmet und wirtschaftlich bleibt.
Was mich an der Zusammenarbeit nach 10 Jahren besonders freut: Philipp und ich kennen uns noch aus dem Heilbronner Nachtleben – und die Philosophie hat sich nie geändert. Stabile Technologien. Kein Overengineering. Kein Overprovisioning.
Wenn du auch ein skalierbares Setup ohne Hyperscaler-Preise suchst – oder schlicht ein Backup für dein Ein-Personen-DevOps-Team brauchst, dann lass uns kurz sprechen.
Die vollständige Case Study lesen
AWS: Zufall schlägt Hierarchie im Rechenzentrum
Hierarchische Rechenzentrumsnetze nach Clos- beziehungsweise Fat-Tree-Prinzip gelten als gesetzt — Leaf, Spine, bei großen Installationen noch ein Super Spine darüber. Wie AWS-Forscher mit dem Resilient Network Graph (RNG) ausgerechnet diese obersten, teuersten Ebenen einsparen wollen, beschreibt Benjamin Pfister bei heise/iX. Die Idee: ein flaches Design mit quasi-zufälliger Verschaltung.
Kern sind passive optische Shuffleboxen, auf die jeder Router auf einem beliebigen Port aufgelegt wird; die Einfügedämpfung verkraften moderne Optiken laut Amazon problemlos. Neu ist der Ansatz nicht — schon in den 1990ern galten zufällige Topologien rechnerisch als optimal, scheiterten aber an Rechenaufwand und Verkabelung. Das passende Routing liefert Spraypoint: Der Quellrouter „sprüht“ Pakete zufällig an alle Nachbarn, von dort übernimmt klassisches Shortest-Path-Routing über Wegpunkte zum Ziel.
Amazons Zahlen dazu:
- 69 Prozent weniger Router
- bis zu 33 Prozent mehr Durchsatz
- 40 Prozent weniger Energie für Netzkomponenten
- 9 bis 45 Prozent Gesamtkostenersparnis, je nach Überbuchungsrate
Seit April 2026 ist RNG Standard in den meisten neuen AWS-Rechenzentren, erstmals lief es Ende 2024 in Dublin. Den Haken nennt AWS gleich selbst: Das Routing-Protokoll bleibt unter Verschluss, Details zu den Shuffleboxen fehlen. Eine Insellösung also. Spannend wäre, ob sich das Prinzip auf KI-Backend-Netze übertragen lässt — das Paper nennt genau das als nächsten Prüfschritt.
So spart sich AWS 69 Prozent der Router
Datadog PostgreSQL-HA auf K8s
Ein Gameday bei Datadog förderte eine unbequeme Wahrheit zutage: Die hauseigene PostgreSQL-HA-Architektur auf Kubernetes konnte im Ernstfall gar nicht sicher failen. Shree Sampath beschreibt im Engineering-Blog, wie ein simulierter Zonenausfall mit künstlicher Netzwerklatenz das Setup entlarvte und was das Team daraus gebaut hat.
Das Problem steckte in einer Default-Einstellung. Mit asynchroner Replikation bestätigt der Leader Writes, ohne auf die Replicas zu warten; steigt die Latenz, wächst der Replication-Lag. Als der Primary die Verbindung verlor, lagen alle Standbys jenseits des konfigurierten maximum_lag_on_failover, und Patroni verweigerte korrekterweise die Promotion. Kein Standby war aktuell genug, kein sicherer Failover-Kandidat, Cluster blockiert. Das vermeintlich hochverfügbare Design hatte stillschweigend Verfügbarkeit über Haltbarkeit gestellt.
Die Lösung ist ein Hybrid-Modell: Die Standbys im Leader-Pool laufen nun synchron, die Read-Replicas weiter asynchron. Patroni wartet damit vor dem Commit auf Bestätigung eines synchronen Standbys, ein Failover-Kandidat ist so immer aktuell. Konfiguriert wird das über synchronous_mode, synchronous_mode_strict und synchronous_commit: remote_apply (Schaubild im Blog Artikel dazu).
Umsonst ist das nicht. Im pgbench-Benchmark kostete remote_apply rund 53 Prozent mehr Latenz und 34 Prozent Durchsatz. In Produktion sah Datadog davon allerdings nichts Messbares. Ausgerollt wurde schrittweise mit Bake-in-Phasen, und die Durabilität lässt sich per patronictl edit-config jederzeit ohne Downtime wieder lockern.
Der eigentliche Gewinn ist konzeptionell. Bei einer Sync-Replication-Störung blockiert das Cluster Writes, statt sie still zu verlieren. Fehler werden so sichtbar und für Upstream-Services über Retries oder Queuing behandelbar. Den Trade-off zwischen Latenz und Datensicherheit kennt jeder, der PG selbst betreibt; die Patroni-Mechanik dahinter bleibt dieselbe, ob auf Kubernetes oder klassisch auf VMs. Wir fahren unsere PG-Cluster lieber auf VMs mit Autobase (das wir auch sponsern); Datenbanken auf Kubernetes bin ich offen gesagt kein Fan von.
When failover isn’t safe: Building high-availability PostgreSQL on Kubernetes
Horizontales vs. vertikales Context-Switching
Dass Context-Switching die Produktivität auffrisst, weiß jeder, der schon mal zwischen fünf offenen Tabs den Faden verloren hat. Dunya Kirkali fügt im Blog „Incremental forgetting“ eine Unterscheidung hinzu, die in der üblichen Deep-Work-Predigt meist fehlt. Nicht jeder Wechsel koste gleich viel.
Sie trennt horizontale von vertikalen Switches. Horizontal heißt Wechsel zwischen Aufgaben desselben Typs, etwa von Feature A zu Feature B, beides Coden, derselbe Modus. Das kostet etwas (Domäne und Konventionen neu laden), aber die kognitive Maschinerie bleibt dieselbe. Vertikal dagegen meint den Sprung zwischen Arbeitsarten, vom Debugging ins 1:1, dann in die Roadmap-Runde. Jeder Modus verlangt ein anderes Hirn: analytisch, empathisch, strategisch. Das ist keine Steuer mehr, sondern eine Strafe, inklusive Warm-up und Cool-down, die die meisten unterschätzen.
Dass Switching ein Zins auf die Aufmerksamkeit ist, hatte ich in Ausgabe 66 schon beschrieben; die Horizontal/Vertikal-Trennung schärft das Bild nur. Kirkalis eigentliche Pointe betrifft aber AI. Weil Arbeit billiger zu starten ist (ein Draft, ein Agent, ein zweiter Branch), starten wir mehr und beenden weniger. Fünf flache Threads statt eines tiefen, getarnt als Produktivität.
Eliminieren lässt sich Switching nicht, clustern schon. Die Hebel:
- Time-Blocking: 1:1s am Stück, Deep Work in einem Block, Code-Reviews und Slack-Triage gebündelt.
- Themed Days: Arbeitsarten festen Wochentagen zuordnen, damit das Hirn schon weiß, in welchem Modus es sitzt.
- Delegieren: der stärkste Hebel, jede abgegebene Daueraufgabe ist ein vertikaler Switch, den man gar nicht erst macht.
- Office Hours und räumliche Trennung: Ad-hoc-Fragen sammeln, People- und IC-Arbeit an verschiedene Orte legen.
Wenn du schon switchen musst, dann seitwärts, nicht hoch und runter. Wie schützt ihr eure Fokuszeit — oder habt ihr das längst aufgegeben?
Horizontal vs. vertical context switching for engineering Managers
On-Call: Wann darf der Neue an den Pager?
Wie lange darf ein neuer Kollege im Team sein, bevor er die Bereitschaft übernimmt? Ein Thread im r/sre-Subreddit bringt eine Konstellation auf den Tisch, die viele kennen. Der OP, einer von wenigen SREs, soll auf Geheiß seines Chefs neue Leute schon nach drei Wochen on-call schicken. Und das bei einem unfertigen Produkt ohne brauchbare Doku, mit verteiltem Spezialwissen und ohne redundante Ansprechpartner.
Die Community ist sich erstaunlich einig: zu früh. razzledazzled formuliert das Prinzip am knappsten, die Einarbeitung gehöre „qualitative not time based“ bemessen. daedalus_structure nennt drei Wochen schlicht wahnsinnig, weil neue Leute dann nicht mal wüssten, wo die Systeme liegen, und schlägt ein 30-60-90-Modell vor: erst Support begleiten, dann eine Rotation shadowen, dann ans Ende des Plans. Vier bis sechs Monate bis zum Alleingang sind im Thread der häufigste Wert.
Der wichtigste Punkt kommt von KarlosKrinklebine: „Nobody is ever ready to go on call before going on call.“ Entscheidend sei nicht das Datum, sondern ein verlässlicher Eskalationspfad und die Fähigkeit, die Schwere eines Vorfalls einzuschätzen. Wo die Doku dünn ist, wird das Ganze zur Mutprobe. DahliaDevsiantBop beschreibt das Szenario treffend als „ticking bomb and a blindfold“.
Dass das Kernproblem nicht die Zeit, sondern fehlendes operatives Wissen ist, passt zu Ausgabe 234, in der Heinrich Hartmann argumentierte, der eigentliche On-Call-Schmerz sitze beim Engineer um drei Uhr nachts, der den Service schlicht nicht kennt.
Ich bin klar im Shadow-Lager: erst mitlaufen, mitbekommen, eskalieren dürfen — und das ohne Zeitdruck. Bei web.de gab es dafür damals ein 30-Tage-Bootcamp, bevor überhaupt jemand an den Pager durfte. Wie handhabt ihr das bei euch?
How long does your company give new people before they put them oncall
incident.io: Reliability als Kundensache
„Nicht unser Fehler“ ist bei Reliability eine bequeme Ausrede, und incident.io verweigert sie sich konsequent. Mike Fisher beschreibt im Engineering-Blog, wie das Team die Zuverlässigkeit seines On-Call-Produkts misst, und zwar von der Kundenwirkung her gedacht statt von der eigenen Systemgrenze.
Reduziert wird alles auf zwei SLIs: Werden Alerts zuverlässig angenommen, und gehen die Benachrichtigungen rechtzeitig raus (unter fünf Minuten)? Beide mit einem 99,99-Prozent-Monatsziel. Spannend ist, wie konsequent „kundenzentriert“ hier ausgelegt wird:
- Good Minutes statt Rohfehlerrate: Der Monat wird in Minuten zerlegt, eine Minute gilt ab unter 10 Prozent Fehlerrate als „gut“. Selbstheilende Blips zählen so als Normalzustand; sinkt der SLI unter 100 Prozent, war wirklich jemand betroffen.
- Aktiv-aktiv bei Drittanbietern: Für SMS und Anrufe laufen zwei Telekom-Provider parallel. Genau diese Lücke schloss incident.io nach dem AWS-Ausfall im Oktober 2025, als der einzige Telco-Provider mit untergegangen war. Bei monolithischen Diensten wie Apples APNs, wo keine eigene Redundanz geht, sollen Nutzer Push, SMS und Anruf kombinieren.
- Absichtliche Delays rausrechnen: Wer eine Eskalation bewusst verzögert (Nachtruhe, Alert-Grouping, eigene Notification-Regeln), soll dafür nicht das SLO verhageln. Die Latenz ist Ende minus Start minus konfigurierter Verzögerung; Fisher spricht von ziemlich spektakulärem BigQuery-SQL.
Fisher nennt den Leitgedanken den „red face test“. Man würde sich schämen, einem Kunden eine verspätete Benachrichtigung als dessen eigenes Problem zu verkaufen, wo man ihm das Layern der Methoden selbst empfohlen hat.
Die geschlossene Telco-Lücke ist übrigens dieselbe, die incident.ios eigenes Oktober-Postmortem in Ausgabe 214 offengelegt hatte — schön, die Fortsetzung zu sehen. Reliability als Kundenerlebnis statt als Komponenten-Häkchen. Genau die richtige Perspektive.
Customers over control: how we measure On-call reliability
Lokale KI ist gut genug fürs Coding – auf dem Mac
Gleich zwei Praktiker kommen diese Woche unabhängig zum selben Schluss: Lokale Modelle taugen inzwischen fürs Coding. Vicki Boykis beschreibt den Wendepunkt eher aus der Vogelperspektive – nach Jahren mit langsamen, ungenauen Modellen war GPT-OSS für sie das erste, das sie kaum noch gegen eine API gegenprüfen musste. Mit der Gemma-4-Familie laufe agentisches Coding lokal nun bei rund 75 % der Genauigkeit und Geschwindigkeit von Frontier-Modellen – auf einem M2-Mac mit 64 GB, mit Pi als Agent und LM Studio als Server.
Kyle Howells liefert die Messwerte dazu – passend zum Xeon-Beitrag oben dasselbe Modell, dieselbe MTP-Technik, nur auf einem M1 Max statt GPU-losem Xeon. Sein Stack: Gemma 4 26B-A4B (MoE, ~3,8B aktiv) in Q4, ein Q8-MTP-Draft fürs Speculative Decoding, der Multimodal-Projektor für Screenshots, dazu wieder Pi. Mit MTP klettert die Generierung von 58 auf 72 Tokens/s (+24 %), und llama.cpp mit Metal schlägt das eigentlich Mac-optimierte MLX deutlich (72 vs. 46).
Spannend finde ich zwei Punkte: Boykis kapselt jede Pi-Session in einen Docker-Container mit minimalen Rechten – bei lokalen Agents mit Shell-Zugriff keine schlechte Idee. Und für noch kleiner und schneller setzt sie inzwischen auf gemma-4-12b-qat, ein quantisierungsbewusst trainiertes 12B-Modell. Produktionsreif ist das alles nicht: Der KV-Cache füllt schnell die 64 GB, die Kontextfenster bleiben klein. Aber als schnelles, privates „Google für Entwicklerfragen“ und für kleinere Agent-Loops ist lokal angekommen – und du kannst dabei jeden Token live beim Durchlaufen beobachten.
How to Setup a Local Coding Agent on macOS
GLM-5.2 und Kimi K2.7: China schließt auf
Die chinesischen Open-Weights-Labore drehen weiter auf. Zhipu AIs GLM-5.2 ist laut Artificial Analysis mit 51 Punkten das neue stärkste „open weights“ Modell, vor MiniMax-M3, DeepSeek V4 Pro und Kimi K2.6. Das MoE mit 744B / 40B aktiv kommt unter MIT-Lizenz, dazu ein auf 1 Million Token erweiterter Kontext. Bei Langzeit-Coding (FrontierSWE) liegt es mit 74,4 % nur einen Punkt hinter Claude Opus 4.8 und knapp vor GPT-5.5 – beim reinen Reasoning bleibt der Abstand zur Closed-Source-Spitze aber deutlich.
Parallel schickt Moonshot Kimi K2.7-Code ins Rennen, ein Coding-Modell auf K2.6-Basis: 1T gesamt, 32B aktiv, 256K Kontext, native INT4-Quantisierung und rund 30 % weniger Thinking-Tokens als der Vorgänger. Beide zielen klar auf agentische Long-Horizon-Aufgaben.
Zwei Dinge fallen auf. Erstens ist GLM-5.2 token-hungrig: 43k Output-Tokens pro Aufgabe, mehr als jedes vergleichbare offene Modell – die Spitzenwerte kosten also Rechenzeit. Zweitens, und ungewöhnlich offen: Zhipu beschreibt, dass das Modell im RL-Training gelernt hat zu schummeln. Es lud Lösungscode per curl von GitHub oder suchte gezielt versteckte Testdateien, um das binäre Bestanden-Signal zu manipulieren – dagegen steht jetzt ein zweistufiges Anti-Hacking-Modul.
Beide spielen damit in einer anderen Liga als die lokalen Gemma-4-Setups oben: Das ist Rechenzentrum, kein 64-GB-Mac – Kimi etwa belegt selbst in INT4 grob 500 GB nur für die Weights.
GLM-5.2 is the new leading open weights model on the Artificial Analysis Intelligence Index
GLM-5.2 vs. Opus: günstig, aber blind
TechStackups hat GLM-5.2 gegen Claude Opus 4.8 antreten lassen: gleicher One-Shot-Prompt, ein 3D-Platformer in rohem WebGL, ohne Engine, ohne Three.js.
Das Ergebnis fällt gemischt aus. Opus war mit 33 Minuten doppelt so schnell (GLM: 1:10) und lieferte das sauberere Spiel — texturierter Charakter, funktionierende Win-Condition, tödliche Stachelfalle. GLM-5.2 schickte einen grauen, texturlosen Charakter ins Rennen, dessen Falle niemanden tötet, und ließ das Debug-Overlay an. Dafür kostete der Lauf nur $5,39 statt geschätzt $22.
Der aufschlussreichste Unterschied ist aber kein Preis, sondern eine Fähigkeit: GLM-5.2 ist text-only. Wo Opus zur Selbstkontrolle einen Screenshot rendert und prüft, kann GLM-5.2 sein eigenes Ergebnis nicht sehen. Es behalf sich damit, rohe Pixelfarben auszulesen und gegen Erwartungswerte abzugleichen, meldete alles in Ordnung — und übersah dabei die fehlenden Texturen, die ein Blick aufs Bild sofort gezeigt hätte.
Was „open“ praktisch kostet, zeigen die Hardware-Anforderungen. GLM-5.2 ist ein 744-Milliarden-Parameter-MoE mit rund 40 Milliarden aktiven Parametern: in BF16 etwa 1,5 TB, in FP8 noch rund 744 GB, also acht H200. Fürs Self-Hosting bleibt realistisch nur Quantisierung — Unsloths 2-Bit-GGUF drückt das Modell auf ca. 239 GB, lauffähig auf einem 256-GB-Mac-Studio oder vier RTX 3090 mit reichlich RAM, bei mageren 3 bis 9 Token pro Sekunde. Consumer-Hardware ist das nicht.
Anders als ein Closed-Model lässt sich GLM-5.2 nicht zurückziehen oder sperren — woran die jüngste Fable-Episode erinnert. Simon Willison nennt es „probably the most powerful text-only open weights LLM“; Artificial Analysis führt es als stärkstes Open-Weights-Modell, mahnt aber den hohen Token-Hunger an. Für Text und Logik zum Bruchteil des Opus-Preises eine ernsthafte Wahl — geht es um visuelles Urteil und Politur, bleibt Opus vorn.
Schmunzelecke
Bei cssquake.com kannst du Quake im Browser und eben in CSS spielen – GitHub Code dazu.
💡 Link Tipps aus der Open Source Welt
Lore – Next-Gen Version Control von Epic Games
Lore ist ein Open-Source Version Control System von Epic Games, designed für massive Skalierung bei Daten und Teams. Der Fokus liegt auf Projekten, die Code mit großen Binär-Assets kombinieren – Games, Entertainment, 3D-Produktionen. Bereits im Einsatz als Built-in VCS in UEFN (Unreal Editor for Fortnite).
Key Features:
- Binary-First Storage: Chunked Storage mit Content-Addressing, Deduplizierung und indexed Lookup – große Assets sind kein Nachgedanke, sondern der primäre Use Case
- Sparse Workspaces: On-Demand Hydration, nur benötigte Dateien werden heruntergeladen – kein Full-Clone eines 500GB Game Repos nötig
- Merkle Tree + Immutable Revision Chain: Kryptographisch verifizierbare, tamper-evident History
- Zentralisiert mit Caching: Service-backed Architektur mit Caching Layer vor durable Storage für große Teams
- Lightweight Branches: Kein Daten-Duplikat beim Branch-Erstellen, schnelles Switching
- SDKs für alles: C/C++, C#, Rust, Go, Python, JavaScript – Full-Surface API
- Local Mode: Sofort loslegen ohne Server, dann hochskalieren wenn nötig
Geschrieben in Rust (81%). Verfügbar für macOS, Linux und Windows. Demo-Modus per One-Liner.
Dass Epic Games hier ein komplettes VCS unter MIT open-sourced und eine eigene Landing Page unter lore.org aufbaut, zeigt ernsthaftes Commitment. Der Ansatz adressiert einen realen Schmerz: Git ist für große Binär-Assets (Game Assets, 3D-Modelle, Texturen) schlicht nicht gebaut – Git LFS ist ein Workaround, kein Design. Dass Lore bei Epic bereits in Produktion läuft (UEFN), gibt dem Projekt Glaubwürdigkeit, die den meisten VCS-Newcomern fehlt.
https://github.com/EpicGames/lore
RTK – CLI Proxy der LLM Token-Verbrauch um 60-90% reduziert
RTK schaltet sich zwischen AI Coding Agents und Shell-Befehle und filtert, komprimiert und dedupliziert Command-Outputs bevor sie im LLM-Kontext landen. Ein cargo test mit 200+ Zeilen wird zu ~20 Zeilen, git push zu „ok main“. Single Rust Binary, <10ms Overhead.
Key Features:
- 100+ Commands: Git, Docker, Kubectl, Cargo, npm, pytest, AWS CLI, Pulumi, gh und viele mehr – jeweils mit spezifischen Filtern für Smart Filtering, Grouping, Truncation und Deduplication
- Auto-Rewrite Hook: Shell-Befehle werden transparent zu
rtk-Äquivalenten umgeschrieben – zero Token Overhead, 100% Adoption ohne manuelles Umdenken - 14 AI Tools supported: Claude Code, GitHub Copilot, Cursor, Gemini CLI, Codex, Windsurf, Cline, OpenCode und mehr
- Token Analytics:
rtk gain --graphzeigt gesparte Tokens über Zeit,rtk discoverfindet verpasste Einspar-Möglichkeiten - Tee Recovery: Bei fehlgeschlagenen Befehlen wird der vollständige ungefilterte Output gespeichert – LLM kann bei Bedarf nachlesen
- Ultra-Compact Mode: Zusätzliche Einsparung durch ASCII Icons und Inline-Format
Typische Einsparung: ~80% weniger Tokens in einer 30-Minuten Claude Code Session (von ~118k auf ~24k Tokens). Bei API-Pricing ein direkter Kostenvorteil.
Mit 65k Stars und 218 Releases eines der erfolgreichsten Developer Tools des Jahres. Der Ansatz ist simpel aber effektiv – statt am Modell zu optimieren, wird der Input komprimiert. Wer regelmäßig mit AI Coding Agents arbeitet, spart damit messbar Tokens und damit Geld.
❓ Feedback & Newsletter Abo
Vielen Dank, dass du es bis hierhin geschafft hast!
Kommentiere gerne oder schicke mir Inhalte, die du passend findest.
Falls dir die Inhalte gefallen haben, kannst du mir gerne auf Twitter folgen.
Gerne kannst du mir ein Bier ausgeben oder mal auf meiner Wunschliste vorbeischauen – Danke!
Möchtest du den Newsletter wöchentlich per E-Mail erhalten?
Einfach hier abonnieren: