allesnurgecloud.com ist ein kuratierter Newsletter mit Inhalten aus der Open-Source, Cloud und IT-Welt.
Für weiteren Content folge mir gerne auf Twitter, Mastodon oder LinkedIn.
Möchtest du den Newsletter wöchentlich per E-Mail erhalten?
Einfach hier abonnieren:
Ahrefs.com spart $400 Millionen ohne Cloud
Damit es hier nicht immer nur um Cloud-Bashing von DHH/Basecamp geht – mal eine andere Quelle, die in ein ähnliches Thema geht.
Efim Mirochnik, laut Linkedin „Data Center Operations“ bei Ahrefs.com, hat auf Medium eine interessante Betrachtung seiner Sicht der Dinge geteilt. Er eröffnet den Artikel mit den Erfolgsfaktoren der Hyperscaler und warum viele meinen, diese seien heute unverzichtbar für das Business:
With excellent marketing, conferences, certifications, and cherry-picked use case scenarios, it’s easy for one to think that clouds are the only reasonable destination for the IT of a modern business.
Ahrefs ist ein SaaS SEO Tool, welches Webseiten scraped, analysiert und vergleicht. Logischerweise benötigt es dafür eine Menge Traffic und Speicherplatz. Man hat nun eigene Berechnungen zu etwaigen Cloud Kosten angestellt, würde man seine „on-premise“ Infrastruktur in die Cloud umziehen.
Aber was heisst heute denn On-Premise?
Na, jedenfalls nicht mehr das eigene Datacenter – Ahrefs ist ähnlich, wie Basecamp bei einem Co-Location-Provider – kümmert sich also weder um den Raum, noch Strom, noch Klima. In der Regel bezahlt man für Fläche eine Miete und die Stromabnahme nach Verbrauch.
Jedenfalls hat Efim die Kosten für die eigenen Server (Viele CPUs, 2 TB RAM, 2 * 100Gbps, 16* 15 TB Disks) auf 5 Jahre verteilt und kam auf folgende monatlichen Kosten:
- pro Server: 1025 $
- Datacenter, ISP, Netzwerk, etc.: 524 $
- Summe: 1550 $ / Monat pro Server
bei AWS sieht die Rechnung mit EC2 Instanzen und EBS Volumes so aus:
- EBS Volume: 11.486 $
- EC2 Server: 5.607 $
- Data Transfer: 464 $
- Summe: 17.557 $
Ja, aber Andy, das kann man doch nicht vergleichen?
Ne, die AWS Server sind deutlich schwächer (weniger CPU, weniger RAM), die EBS Instanzen sind deutlich langsamer wie die NVME Disks und die IOPS Kosten bei AWS sind auch nicht eingerechnet – Die Rechnung fällt also sehr defensiv aus für AWS.
Ja, und auch der 3 Jahre Discount ist dort schon einberechnet. Die genaue Auflistung findest du hier.
Ahrefs würde also bei AWS das 11,3-fache pro Server bezahlen oder könnte sich anstatt einem vollen 20 Server-Rack nur 2 Server leisten. Auf 30 Monate gerechnet (seitdem ist Ahrefs wohl beim Co-Location-Provider) wäre der Unterschied in Summe 400 Mio $.
Ja, vermutlich würden da noch ein paar Discounts in Spiel kommen.
Nein, es wird dadurch nicht billiger. Auch nicht, wenn man die Workload nach Kubernetes umzieht, oder nach Lambda.
Die Workload ist, wie sie ist – und die ist auf Bare-Metal in der Größe eben um ein Vielfaches günstiger.
Cloud hängt immer vom Use Case ab – wenn man solch einen Park auslastet, macht es keinen Sinn, das in der Cloud zu haben – da gäbe es das Business heute so nicht – oder es hätte einen massiven Kostennachteil gegenüber „No-Cloud“ Mitbewerbern.
How Ahrefs Saved US$400M in 3 Years by NOT Going to the Cloud
Sysdig: 87% der Container mit kritischen Schwachstellen produktiv
Sysdig hat Anfang März den „2023 Cloud-Native Security and Usage Report“ veröffentlicht – und die Zahlen sind schockierend:
87 % der produktiv laufenden Container Images haben Schwachstellen der Einstufung CRITICAL oder HIGH SEVERITY.
Das muss man sich mal auf der Zunge zergehen lassen.
Im Vergleich zum letzten Jahr sind die Zahlen von 75 % Prozent der betroffenen Container sogar noch auf 85 % gestiegen.
Noch schlimmer: für 71 % der Lücken gibt es einen möglichen Fix, der aber halt nicht gepulled wurde.
Wenn man bedenkt, dass heute alle automatische Scanner haben (sollten), die einem dies zeigen, oder zumindest mal einen CI/CD Prozess, der „regelmäßig“ neue Images pulled, oder einen Dependabot, der sich um solche Dinge automatisch kümmert – da kann man solche Zahlen nicht nachvollziehen.
Irgendwie ist mit dieser Cloud-Native Bewegung die Sicherheit zwar transparenter geworden – gebessert hat sie sich dadurch auf jeden Fall nicht, gefühlt sogar eher verschlechtert.
Sysdig hat für den Report die Daten seiner Kunden ausgewertet, wie so ein US SaaS Anbieter das halt nun mal macht.
In Summe wurden Daten von „tausenden Kunden“ und „Milliarden von Containern“ analysiert, die Daten sind also schon aussagekräftig.
87% of Container Images in Production Have Critical or High-Severity Vulnerabilities
Sponsored
Werde DevOps Engineer bei anny!

Wir bei anny kreieren eine allumfassende SaaS-Lösung für Onlinebuchungen und Ressourcen-Management. Warum? Weil wir daran glauben, dass wir in der heutigen Welt dank Digitalisierung viel mehr miteinander teilen können. Das Team hinter anny bündelt Skills und Leidenschaft! Jeder Einzelne im a.team ist neugierig, voller Tatendrang und treibt unsere Vision einer Welt mit geteilten Ressourcen voran.
Wir suchen dich für unser DevOps-Team!
Du liebst Kubernetes, hast Erfahrung mit der Cloud und Lust Teil unseres hybriden a.teams zu werden? Ein Blick auf anny.co verrät dir mehr über die Rolle als DevOps Engineer bei uns und außerdem mehr zu unseren aktuellen Projekten, die du aktiv mitgestalten kannst.
Klingt gut? Dann buche dir direkt ein Kennenlerngespräch bei uns!
Uber zieht in die Google Cloud
In die andere Richtung als bei ahrefs.com geht es nun Uber – von den On-premise Datacenter in die Google Cloud.
Im Februar 2023 veröffentlichte Google CEO Thomas Kurian die News, dass Uber einen langfristigen Vertrag mit der Google Cloud unterschrieben hat.
In einer aktuellen „The Pragmatic Engineer“ Ausgabe beschreibt Autor Gergerly Orosz, der als ehemaliger Uber Mitarbeiter einen guten Einblick haben dürfte, die ersten Hintergründe dazu.
Im kostenlosen ersten Teil erfahren wir über das „Warum“, im kostenpflichtigen zweiten Teil das „Wie“.
- Uber ist 2010 in den USA gestartet, bei einem Hostingdienstleister namens „Peak Hosting“
- 2014 war man dann schon groß genug, „eigene Datacenter“ zu bauen
- Das erste DC entstand in San Jose (SJC), das zweite in Washington (DCA)
- Im Jahr 2014 war „Cloud Computing“ noch nicht, was es heute war – und Google und Facebook haben das ja auch so gemacht – und da wollte man mit Uber ja auch hin.
- Die meiste Zeit liefen die vorhandenen Microservices in einem Data-Center – über einen regelmäßig zu testenden Failover Prozess konnten die Services auf ein anderes DC geändert werden
- Aus Platz und Verfügbarkeitsgründen entschied man sich für ein drittes DC in Phoenix (PHX).
Uber hatte im Laufe der Jahre diverse Herausforderungen mit dem Betrieb eigener DC, beispielsweise:
- Festplatten Ausfälle – teils kaufte man günstige SSD Drives, die häufig ausgefallen sind, oder nicht für hohe Schreiblasten gedacht waren – Wer billig kauft, oder am Use-case vorbei – der kauft halt zweimal.
- Aufgrund der Menge an HW, die man kaufte, wechselte man 2018/2019 von OEM HW (Original Equipment Manufacturer, so etwas wie Dell, HP, Lenovo) auf ODM HW (Original Design Manufacturing – also direkt bei Foxconn oder Quanta).
- Dass diese Option auf Dauer günstiger ist, haben Microsoft, Oracle, Meta und co schon gemerkt – also auch Uber…
- Allerdings hatten die oben genannten Firmen dann auch 100+ Leute auf diesesn Projekten sitzen, um neue Designs zu testen und benchmarken – Uber hatte ein geringeres Volumen und nicht so viele Leute abgestellt – somit viele Probleme mit Qualität und Laufzeiten
Im Artikel gibt es noch weitere Details, jedenfalls kam dann ein neuer CEO zu Uber, Dara Khosrowshahi, vorher bei Expedia. Expedia lebte zu dem Zeitpunkt schon lange in der Cloud – und deshalb soll das nun auch bei Uber passieren.
Zudem hatte Uber 2020 das Startup „Postmates“ übernommen. Postmates glänzte mit geringen Infrastruktur-Kosten innerhalb AWS und man schaute sich das Thema nochmals genauer an.
Am Ende erklärt der Artikel dann noch die „Cloud Basics“ und wie es bei Uber jetzt weitergeht.
Mal schauen, ob ich mir mal noch das Abo gönne, dann kann ich euch von Teil 2 erzählen.
Inside Uber’s move to the Cloud: Part 1
Sysdig Report II: Ressourcen-Verschwendung bei K8s
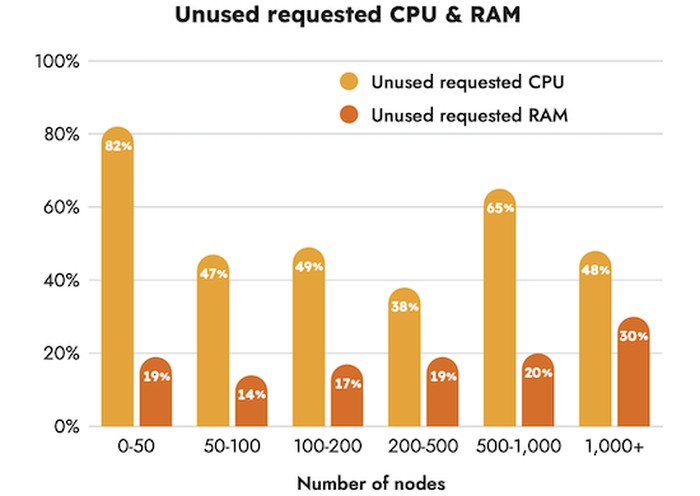
Der zweite Teil des Sysdig Reports (s.o.) beschäftigt sich mit der „Container Usage“.
Auch hier zeigen die Daten einen Snapshot auf die heutige Kundenwelt im Jahr 2023, wie Sysdig sie halt sieht.
- 49 % der Container laufen ohne Memory Limits
- 59 % der Container haben keine CPU Limits gesetzt.
Memory Limits sind jetzt nicht so schlimm, wie fehlende CPU Limits, können aber trotzdem nicht so schöne Nebenwirkungen haben.
- 69 % der konfigurierten CPU Ressourcen werden nicht abgerufen
- 18 % der konfigurierten Memory Ressourcen werden nicht verwendet
Memory Usage finde ich nun fast schon zu schwäbisch, aber so lange das auto-scaling passt, hat man das ja gut ausgelastet.
Bei den CPU Ressourcen sieht man großes Einsparpotenzial, und zwar über alle Clustergrößen.
Sysdig hat dann weiterhin ausgerechnet, dass größere Cluster Einsparpotenzial in Millionenhöhe haben. Bei den größeren Systemen mit über 1000 Nodes sind es im Schnitt sogar über 10 Millionen Dollar pro Jahr, die man dem Cloud-Provider „schenkt“.
Was kann man tun?
Mit vernünftiger Kapazitätsplanung kann man die benötigte CPU Menge berechnen und einen Forecast erstellen. Ja, das hat man eigentlich auch immer schon gemacht, scheinbar nur „verlernt“ oder man kennt es halt noch gar nicht.
Auto-Scaling: Der Kubernetes „horizontal pod autoscaler“ kann in beide Richtungen skalieren, das muss nur passend konfiguriert werden.
Cloud ist halt nicht nur „nach oben skalieren“, sondern halt auch „nach unten“, sonst wird es schnell teuer.
Millions wasted on Kubernetes resources
MagentaCloud: Office auf Basis von Nextcloud
Nextcloud Office kommt als erstes neue Nextcloud Feature in die MagentaCloud.
MagentaCloud? Ja, das ist ein quasi Dropbox/Google Drive Ersatz für Privatkunden aus dem Hause Telekom. Dort kannst du verschiedene Pakete buchen:
- free mit 3 GB Speicher
- für 1,95 € gibt es 100 GB Speicher
- für 4,95 € 500 GB
- für 39,95 € dann sogar 5 TB
Ehrlicherweise kannte ich das auch nicht.
Jedenfalls scheint die heutige Plattform eine Eigenentwicklung zu sein. Die Telekom machte jedenfalls keine Angaben zur aktuellen Technik.
Im Laufe des Jahres sollen nun alle Kundendaten auch auf das Nextcloud Backend migriert werden.
MagentaCloud: Telekom migriert Millionen auf Nextcloud und Collabora Online
5000 $ Stundenlohn für Web-Scraping?
Ja, manche Kunden zahlen einfach gut – in dem Fall eine Anwaltskanzlei.
Diese wollte Daten einer Website gescraped und in eine Excel Datei persistiert haben. Aktuell mache das jemand manuell, jeden Tag, und benötigt hierfür 45 Minuten. Die Hochrechnung von Autor „Yancy Dennis“ ergab, dass die Kanzlei jedes Jahr 4000 $ Kosten für den Prozess hatte – er bot den Scraper deshalb für 2500 $ und bekam den Zuschlag.
Schon in der Mittagspause und nur nach 30 Minuten hatte er das Script fertig, wartete aber ein wenig, bis er das Ergebnis mitteilte:
Had to wait a little did not want him to know that it was little to no effort on my part. But as I explained to him, he is paying for my expertise not my time. Lawyers are not the only ones who can get great pay for their services lol.
Und da ist etwas Wahres dran, nicht wahr?
Jedenfalls hat er für das Script dann in Summe einen Stundenlohn von 5000 $ eingestrichen – nicht schlecht, oder?
$5000 Per Hour Web Scraping Legal Site
Schmunzelecke
- Kleines Browser Game für die Pause? Versuche hier mal zu landen.
- Feel the difference – HTML vss. CSS (reddit)
💡 Link Tipps aus der Open Source Welt
Authelia- Open Source Authorization und Authentication
Authelia ist eine Open Source Authorization und Authentication Lösung, welche 2 Faktor Autorisierung und Single Sign-on über eien Portal Lösung ermöglicht.
Authelia kann dabei in verschiedene Reverse Proxies eingebaut werden, wie beispielsweise NGINX, Traefik, HAProxy oder Caddy.
Das Deployment erfolgt in Docker, Kubernetes oder per Helm Chart. Authelia kann zusätzlich OpenID Connect.
Alle Features findest du auf GitHub in der Übersicht.
https://github.com/authelia/authelia
Zalando: Open-Source Tech Radar
Das Konzept vom „Technology Radar“ von ThoughtWorks kennst du schon?
Man unterteilt Programmiersprachen, Systeme, SaaS Tools, etc. in die 4 Bereiche „Adopt“, „Assess“, „Trial“ und „Hold“.
Zalando hat die Software zu seinem Tech-Radar auf GitHub Open-Source verfügbar – als Demo kann man sich den aktuellen „Zalando Tech Radar“ direkt im Internet anschauen.
https://github.com/zalando/tech-radar
❓ Feedback & Newsletter Abo
Vielen Dank, dass du es bis hierhin geschafft hast!
Kommentiere gerne oder schicke mir Inhalte, die du passend findest.
Falls dir die Inhalte gefallen haben, kannst du mir gerne auf Twitter folgen.
Gerne kannst du mir ein Bier ausgeben oder mal auf meiner Wunschliste vorbeischauen – Danke!
Möchtest du den Newsletter wöchentlich per E-Mail erhalten?
Einfach hier abonnieren: