allesnurgecloud.com ist ein kuratierter Newsletter mit Inhalten aus der Open-Source, Cloud und IT-Welt.
Für weiteren Content folge mir gerne auf Twitter, Mastodon oder LinkedIn.
Möchtest du den Newsletter wöchentlich per E-Mail erhalten?
Einfach hier abonnieren:
Kurzfristige Cloud Migration der Raiffeisen Bank Ukraine
In einem interessanten Interview berichtet Hryhorii Tatsyi, CTO der Raiffeisen Bank Ukraine, von der erzwungenen und kurzfristigen Cloud Migration der Bank aufgrund des Krieges in der Ukraine.
Die Raiffeisen Bank Ukraine ist eine Tochter der Österreichischen Raiffeisen Bank, hat aber selbst über 1000 Server in der Ukraine betrieben. Bei der Bank arbeiten über 6000 Mitarbeiter, 800 davon in technischen Rollen.
Bereits im Februar hatte Hryhorii mit seinem Team Domain Driven Design eingeführt und in der Bank verschiedene Domains geschaffen, wie beispielsweise „Kredite“, „Zahlungsverkehr“, „Technologie“ und „Security“. Diese Domains konnten die Migration dann selbstständig innerhalb ihrer Domain durchführen.
Interessant finde ich, dass er relativ schnell eine „FinOps Community“ geschaffen hat, die die Cloud Kosten bereits 2 Monate nach der Migration von 700.000 $ / Monat auf die Hälfte davon reduzieren konnte:
After our migration, our bill was $700,000 per month, because we were paying for capabilities we didn’t need. But within two months, our bills significantly decreased, to less than $350,000 per month, which we achieved through the FinOps community I created.
Die FinOps Community trifft sich regelmäßig, um neuste Ergebnisse und Erfahrungen zu teilen und in die anderen Teams zu bringen. Die Bank verwendet zum Tracking und der Analyse der Cloud Kosten das „CUDOS“ Dashboard Framework von AWS – hier kannst du ein Beispiel der Visualisierung sehen.
Total absurd ist, dass man die Migration innerhalb von 3 Monaten durchgezogen hat – man hatte ja schließlich keine andere Wahl.
We did this migration in three months, because we didn’t have a choice. We all worked seven days a week, 12 hours a day or more, to migrate more than 1,000 servers during the first three months. We didn’t have any business outages, spent zero dollars for additional vendor support, and made everything work with our hands, with our heads, and with our hearts.
Die Bank selbst hat über 3 Millionen Kunden, und man wollte um jeden Preis verhindern, dass die Kunden und Bewohner das Vertrauen in das Banking System verlieren. Zusätzlich beeindruckend: Es gab keinen einzigen Ausfall während der Migration, und das, Trotz des hohen Drucks und der kurzen Zeit. Einen Großteil der Umzüge fand nachts statt, in der Zeit war das Internet Banking eingeschränkt, ansonsten funktionierte aber alles.
Die Mitarbeiter führten die Migration komplett remote durch – teilweise aus der Ukraine, teilweise auch aus dem Ausland wie Österreich oder Serbien.
Reddit Ausfall und vergessliche Organisationen
Bei Reddit kam es am Pi-Day, dem 14. März 2023, zu einem längeren Ausfall von Reddit.
Alles Begann mit einem vermeintlich einfachen Upgrades der Kubernetes Cluster von Version 1.23 auf 1.24. Das Upgrade führte zu einer Downtime von über 5 Stunden Länge (314 Minuten), in der die Reddit User einen 500er gezeigt bekamen.
Was war passiert?
Beim Upgrade wurden die „Route Reflectors“ des verwendeten Service Mesh „Calico“ gelöscht. Die „Route Reflectors“ wurden vor Jahren eingeführt und haben jetzt auch jahrelang ohne Probleme funktioniert:
The route reflectors were set up several years ago by the precursor to the current Compute team. Time passed, and with attrition and growth, everyone who knew they existed moved on to other roles or other companies. Only our largest and most legacy clusters still use them. So there was nobody with the knowledge to interact with the route reflector configuration to even realize there could be something wrong with it or to be able to speak up and investigate the issue.
Es gab also keine Dokumentation und auch niemanden mehr, der sich damit auskannte. Hinzu kam, dass die Konfiguration wohl „manuell“ erfolgte und daher auch nirgends „in Code“ dokumentiert war.
Am Ende hatte man etwas Glück bei der Suche nach der Nadel im Heuhaufen, ein Engineer erinnerte sich zum Glück dann doch noch an die eingesetzte Software. Aus den Logs ist man mehrere Stunden nicht schlau geworden.
Was mich etwas überrascht hat, ist das man so lange gewartet hat, um ein Backup einzuspielen.
Eigentlich sollte man Incident und Problem an der Stelle ja immer beheben, und nach X Minuten aufhören, das Problem „live“ zu debuggen – da sind die 314 Minuten dann schon eine recht lange Downtime.
Falls du dich für die Details interessierst, Reddit hat einen ausführlichen Postmortem zur Downtime veröffentlicht.
Ironischerweise hatte der CTO Chris Slowe 2 Monate zuvor in einem weiteren Blog-Post die deutliche Verbesserung der Reddit Service Availability öffentlich aufgezeigt und die Verbesserungen seines Teams gelobt.
Wo gehobelt wird, fallen Späne – sagt man so schön – ist in diesem Fall recht passend.
Wie kann man verhindern, dass solch kritisches Wissen verloren gehen kann und die Organisation dies nicht vergisst?
Selbst wenn man dies Dokumentiert hat, muss man immer noch wissen, wonach man suchen muss. Dokumentationen solcher Systeme haben ja für gewöhnlich eine ordentliche Größe.
Wie stellst du in deiner Firma sicher, dass solches Wissen nicht verloren wird? Antworte mir gerne auf die Mail oder hinterlasse einen Kommentar im Blog – danke.
Stundenlanger Ausfall, weil niemand mehr den Code kennt
Sponsored
Werde DevOps Engineer bei anny!

Wir bei anny kreieren eine allumfassende SaaS-Lösung für Onlinebuchungen und Ressourcen-Management. Warum? Weil wir daran glauben, dass wir in der heutigen Welt dank Digitalisierung viel mehr miteinander teilen können. Das Team hinter anny bündelt Skills und Leidenschaft! Jeder Einzelne im a.team ist neugierig, voller Tatendrang und treibt unsere Vision einer Welt mit geteilten Ressourcen voran.
Wir suchen dich für unser DevOps-Team!
Du liebst Kubernetes, hast Erfahrung mit der Cloud und Lust Teil unseres hybriden a.teams zu werden? Ein Blick auf anny.co verrät dir mehr über die Rolle als DevOps Engineer bei uns und außerdem mehr zu unseren aktuellen Projekten, die du aktiv mitgestalten kannst.
Klingt gut? Dann buche dir direkt ein Kennenlerngespräch bei uns!
Tech-Job: jahrelang angestellt, aber nie richtig „gearbeitet“
Ein (ehemaliger?) Techmitarbeiter fasst die Tech-Bubble Jobs süffisant, aber auch ein ernst zusammen:
After being employed in the tech sector for years, I have come to the conclusion that most people in tech don’t work. I don’t mean we don’t work hard; I mean we almost don’t work at all. Nada. Zilch.
And when we do get to do some work, it often brings low added value to the company and its customers.
All of this while being paid an amount of money some people wouldn’t even dream of.
Oha, überbezahlt, nicht viel zu tun, kaum richtig am Arbeiten. Na, erkennst du dich wieder?
Emmanuel untermauert seine Argumentation mit Beispielen und ist dabei erfrischend ehrlich. Bisher war er immer als Freelancer unterwegs, seit einigen Monaten hat er aber einen festen Job bei einer Investment-Bank – ob er diesen jetzt noch hat?
Since the beginning of my employment, five months ago, I’ve worked for around three hours in total (not counting non-focused Zoom meetings which I attended without paying much attention).
Er schreibt weiter, dass er die ihm zugeordneten Tasks in Minuten erledigen kann, man ihm dafür aber teils mehrere Tage Zeit für gibt. Als er die Dinge beschleunigen wollte, mehr Themen ziehen wollte und sogar die Frechheit besaß, Vorschläge zu machen, haben die Kolleg:innen ihn ausgebremst. Und Fragen solle er auch nicht stellen, das gehöre sich nicht.
In einem vorherigen Job als Data Engineer habe er ähnliche Erfahrungen gemacht:
In the year and a half that I worked for them, there was only one two-week period during which I worked at full capacity. Other than that, I did almost nothing at all for the remaining 18 months.
Erstaunlich, oder?
Emanuel erläutert 3 Gründe, an denen es seiner Meinung nach liege:
Tasks würden in der Realität viel zu komplex und umfangreich geschätzt. Teilweise würde man sich mit den Schätzungen sogar einfach nur übertreffen wollen. Einfache Tasks würden in Sub-Tasks aufgesplittet und viel komplexer gemacht, als sie eigentlich seinen. Seiner Meinung nach sei dieser „Bloating Factor“ bei mindestens Faktor 10 – er habe aber aber auch schon Faktor 50 oder 100 erlebt!
How the agile recipe kills productivity
Ja, da lässt er sich auch ordentlich drüber aus. Seiner Erfahrung nach kommen die „agile recipes“ mit sehr viel „meta“ Arbeit. Demos, Reviews, Retros, Dailys – alles Termine und Meetings, die es früher nicht gab – die Zeit zum Arbeiten fehle – und schließlich müssen die Termine ja auch vorbereitet werden.
Den Joke hier fand ich dann aber doch auch witzig:
I have joked that the reason Facebook became “Meta” is that all its employees do is “meta work.”
Wieder ernst wird es dann hier:
The universal adoption of agile recipes has hijacked techies’ work. No one is incentivized to work at full capacity or keep the product and client as the top priority. Instead, employees’ main goal becomes to abide by the methodology.
Und ja, was soll ich sagen, da ist definitiv etwas dran. Die Belange des Kunden geraten in den Hintergrund.
Cloud-Migration, Microservice-Architektur, etc. – alles schön und gut, aber was hat am Ende der Kunde für einen Mehrwert davon? Gibt es überhaupt einen messbaren Mehrwert? Sollte man das Ganze dann überhaupt machen?
Hier geht es um den Hype, der die Märkte dominiert. Erst einmal Mitarbeiter einstellen, dann was mit ChatGPT machen wollen – und sich dann erst fragen, was das Produkt überhaupt genau sein soll und welchen Mehrwert es liefert.
Emmanuel schließt den Artikel mit Beispielen, bei denen er hochproduktiv war. Beispielsweise als Freelancer in Start-ups, die zwar agil gearbeitet haben, sich aber von den Methoden und Prozessen nicht haben in Geiselhaft nehmen lassen.
Und es helfe auch, emotional involviert zu sein, um ein gutes Produkt zu bauen.
Und zum Disclaimer gehört hier, dass Emmanuel ein Buch geschrieben hat, welches diese Themen ebenfalls behandelt: In „Smart Until It’s Dumb“ erklärt er, warum die AI auch in Zukunft Fehler macht und er prophezeit, dass auch diese Blase platzen wird.
In Summe fand ich den Artikel erfrischend ehrlich und wenn man in den Spiegel schaut, findet man vielleicht die eine oder andere Wahrheit, die auch im eigenen Job zutrifft.
I’ve been employed in tech for years, but I’ve almost never worked
Log4Shell, NPM und Software Supply-Chain
Ein aktueller Artikel bei heise beleuchtet mal wieder das Thema Software-Lieferkette & Supply-Chain.
Nach Informationen von Christian Grobmeier vom Open-Source-Projekt Log4J hat in einem Vortrag darauf hingewiesen, dass auch heute noch gegen Log4Shell verwundbare Log4J Versionen heruntergeladen werden – und zwar 34 % der Projekt-Downloads pro Tag. Dies finde ich einen erstaunlichen Wert – hier scheint jemand seine batch und shell Skripte auch 15 Monate nach dem Fix noch immer nicht angepasst zu haben.
Dabei gibt es heute doch Systeme, die solche depdencies automatisch aktualisieren können, beispielsweise Renovate oder dependabot.
Im weiteren Vortrag verwies Grobmeier auf die Aufwände, die Open-Source Entwickler für vernünftige Security aufbringen müssten – und dass den Projekten häufig das Funding und Know-how fehle. Man benötige zudem regelmäßige Audits und Geld, die Findings dann auch zu fixen.
Das Thema Software Supply Chain macht auch vor moderneren Workloads keinen halt:
Gabi Dobocan beschreibt in diesem Artikel, dass in der Woche zwischen dem 22 und 29. März mehr als die Hälfte der ins NPM Repo geladenen Packages SEO Spam Pakete gewesen sind. In Summe waren das in dieser Woche alleine über 185.000 Pakete – selbst während dem Schreiben seines Artikels seien 1583 neue „E-Book Spam“ Pakete dazu gekommen.
Ja, natürlich ist sein Beitrag auch ein wenig Content-Markteing für die eigene NPM Auditing Software Sandworm, die Zahlen ansich sind aber schon beunruhigend.
Was kann man tun?
Open-Source supporten, contributen oder sponsorn – das geht bei vielen Projekten einfach über GitHub Sponsors. Leider ist die Spenden-Welt auch nicht homogen – bei Log4J kann man beispielsweise an einzelne Maintainer über GitHub spenden, nicht aber direkt an das Projekt.
Log4Shell: Open Source als Gefahr für die Software-Lieferkette
Project-A: Cloud Kosten Best-Practices
Im Blog von Investor und Inkubator Project-A zeigt Senior DevOps Engineer Alencar Souza, wie man Cloud Kosten sparen kann und wie Project-A dieses Know-How in seine Portfolio-Start-ups transferiert.
Zusätzlich führt Alencar auch Security und Cloud Audits durch. Häufige Fehler sind hierbei:
- Nutzer mit weitrechenden Privilegien
- Fehlende Multi-Faktor Authentifikation (Siehe 2FAS Open-Source von der letzten Ausgabe)
- öffentliche exposed Secrets
- weitreichende Netzwerk Freischaltungen
- Öffentliche Services
- und mehr.
Best Practices für Infrastruktur sind für ihn:
- Infrastruktur als Code (IaC)
- CI/CD
- Observability/Monitoring
- Dokumentation
Wichtig sei hierbei, dass man den „Bus Test“ im Kopf behält. Ist ein Know-How Träger von jetzt auf nachher nicht mehr da, kann das Geschäft weiterlaufen wie bisher? Können Änderungen durchgeführt werden?
Interessant fand ich seine Sicht auf Cloud Provider, die ich so nicht erwartet hätte:
I’d recommend starting with smaller cloud providers. I’m not a big fan of those big cloud providers, and I think companies use them because it’s trendy: You use AWS because everyone else uses it, although you’re not aware of 90% of the stuff that goes on behind the first page.
Damit sitzen wir wohl im selben Boot – denn ich sehe das exakt so.
Am Ende seines Artikels findet sich dann noch die Vorgehensweise/Q&A von ChatGPT im Falle eines Infrastruktur-Audits in AWS – ebenfalls interessant und einen Blick wert.
Keep Your Cloud Under Control: Infrastructure Best Practices
Pragmatischer Ansatz zu Uptime & Reliability
Itzy Savo wirbt im verlinkten Artikel für einen pragmatischeren Ansatz beim Thema „Uptime“.
Sein Leitsatz dabei:
Engineering for 99.5% uptime is more cost-effective than 99.99% for most startups!
Und ich denke, das gilt nicht nur für Start-ups. Nicht immer muss es eine Multi-Replikation oder ein Master-Master System sein, das seine eigene Komplexität und Probleme mit sich bringt. In vergangenen Jobs hatte ich auch als mit Cluster-Systemen zu tun, die selbst die Ausfälle verursacht haben.
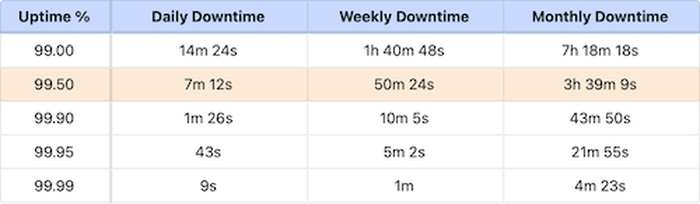
Itzy rechnet vor, dass ein System mit 99,99 % Uptime 50x verlässlicher sein muss, als eines mit 99,5 %. In Zahlen ausgedrückt sieht das dann so aus.
50 Minuten Downtime in der Woche finde ich persönlich jetzt schon zu viel, aber es kommt schließlich auf den Use Case an. Wie immer an der Stelle verweise ich gerne auf das Pingdom Uptime-Cheat Sheet (PDF), welches die Werte pro Monat/Jahr darstellt.
Interessante Punkte im Artikel:
Single Point of Failure müssen nicht technischer Natur sein – das kann so etwas Einfaches wie eine Kreditkarte eines Managers sein, der zum Zeitpunkt der Verlängerung oder Kreditrahmenüberziehung nicht erreichbar ist.
Häufig lassen sich produktive Probleme im Testsystem nicht nachstellen – auch dies kann ein organisatorisches und nicht technisches Problem sein – beispielsweise bei den Kosten.
Nutzt man mehrere Systeme, Regionen oder SaaS Angebote, um daraus ein SaaS Produkt oder eine E-Commerce-Webseite zu bauen, dann wird es erst richtig komplex. Schließlich ist die schwächste Kette im Glied dann für den potenziell niedrigeren SLA verantwortlich.
Außerdem ist der eigene Code auch eine wichtige Komponente – ist jemand 24/7 erreichbar, der ein Problem fixen kann? Ist die Dokumentation an der Stelle gut genug, damit dies möglich ist? Gibt es überhaupt einen On-call?
All diese Faktoren haben Einfluss auf die „reliability“, die Verfügbarkeit einer Applikation.
Schlussendlich gehören all die genannten Punkte zu einer ganzheitlichen Betrachtung des Themas Uptime dazu.
Am Ende ist es immer eine Rechnung: ausbleibende Umsätze aufgrund Downtime vs. Ausgaben für höhere Verfügbarkeiten.
Uptime Guarantees — A Pragmatic Perspective
Gordon Moore mit 94 Jahren gestorben
Gordon Moore, der Begründer von „Moore’s Law“ ist im Alter von 94 Jahren gestorben.
Was war noch mal das Mooresche Gesetz, Andy? Ich habe im Studium geschlafen.
„Moore’s Law“ besagt, dass sich „die Anzahl der Komponenten auf einer integrierten Schaltung alle 2 Jahre verdoppelt“ – später waren dies dann 18 oder auch mal 12 Monate. Im Grunde bedeutet dies, dass sich die Leistung einer CPU alle 12-24 Monate verdoppelt, da man mehr Transistoren bei gleicher Größe unterbringen kann.
Das Erstaunliche daran ist, dass Gordon Moore das Gesetz bereits 1965 formuliert hat.
Aktuell geht man übrigens davon aus, dass das Gesetz in den nächsten Jahren seine Gültigkeit verliert – vielleicht sogar schon im Jahr 2025 – irgendwann geht es halt nicht mehr kleiner.
Gordon Moore war übrigens Mitgründer von „NM Electronics“ und aus NM wurde dann die „Intel Corporation“, deren Chariman und CEO Moore dann bis 1987 war. Sein Vermögen wird im Februar 2023 auf über 7 Milliarden Dollar geschätzt.
Eine gute Zusammenfassung seines Lebens findest du im verlinkten Artikel der „Gordon and Betty Moore Foundation“.
Wikipedia hat eine sehr ausführliche Zusammenfassung seines Lebens – und die Arbeit zu „Moores Law“ gibt es hier als PDF.
In Memoriam: Gordon Moore, 1929 – 2023
Schmunzelecke
Tja, AI macht auch vor Lorem Ipsum keinen Halt – es gibt nun „AI Ipsum“ für Deine Demo und Platzhalter Daten.
Das Projekt ist hier auf GitHub und dort Online. Und es gibt auch eine API.GET https://ai-ipsum.app/ipsum/{quantity} liefert Dir eine Anzahl (Quantity) an Ipsum Blöcken.
💡 Link Tipps aus der Open Source Welt
Botkube – ChatOps für Kubernetes
Botkube ist ein Open Source Monitoring und ChatOps Tool, welches sich direkt in Slack, Teams, Mattermost und Discord integrieren lässt. Als weitere Integrationen gibt es beispielsweise noch die Möglichkeit Helm Charts auszuführen und Prometheus anzubinden.
In der Dokumentation findest du eine Feature Map pro Chat Tool und weitere Infos.
Beispiele, was man mit Botkube alles machen kann, findest du auf der Landingpage von Botkube – Viel Spaß!
https://github.com/kubeshop/botkube
Open Source One-Time Secret App
Gelegentlich habe ich den „One-Time Secret“ Dienst onetimesecret.com ja schon genutzt, bisher war mir aber nicht klar, dass das Projekt dahinter Open Source ist.
Die App ist in Ruby geschrieben und benötigt nur noch einen Redis Dienst und SMTP Credentials, falls man etwas mit Accounts machen möchte. Accounts haben den Vorteil, dass man Secrets bis zu 14 Tagen Gültigkeit bekommt, man Links per Mail verschicken kann und die API Funktionalität verfügbar ist. Ohne Account sind die Secret Links maximal 7 Tage gültig – in der Regel auch mehr als genug.
Installiert wird „One-Time Secret“ einfach per docker-compose oder via Ruby.
https://github.com/onetimesecret/onetimesecret
❓ Feedback & Newsletter Abo
Vielen Dank, dass du es bis hierhin geschafft hast!
Kommentiere gerne oder schicke mir Inhalte, die du passend findest.
Falls dir die Inhalte gefallen haben, kannst du mir gerne auf Twitter folgen.
Gerne kannst du mir ein Bier ausgeben oder mal auf meiner Wunschliste vorbeischauen – Danke!
Möchtest du den Newsletter wöchentlich per E-Mail erhalten?
Einfach hier abonnieren: