Willkommen zu allesnurgecloud.com – Ausgabe #123!
Da habe ich in der letzten Woche Links zu Twitter über „nitter“ angekündigt, dann ist dort das Zertifikat ausgelaufen und die Weiterleitung hat erst einmal nicht funktioniert. Passiert halt immer wieder, auch wenn es Unmengen an Tools zur Überwachung von Zertifikaten gibt.
So, aufgrund des Cloudflare Ausfalls vom Donnerstag habe ich kurzfristig ein paar Themen umgeworfen, ist aber vielleicht gerade deshalb eine prall gefüllte Ausgabe.
Im „Happy Bootstrapping“ Podcast hatte ich diese Woche Matthias und Manuel von T1TAN zu Gast. Deren HQ ist bei mir um die Ecke und ich hatte gar nicht auf dem Schirm, was für ein verrücktes Business „Torwarthandschuhe online verkaufen“ sein kann. Man braucht davon mindestens 4 Stück im Jahr, und da kommt schon etwas zusammen.
allesnurgecloud.com ist ein kuratierter Newsletter mit Inhalten aus der Open-Source, Cloud und IT-Welt.
Für weiteren Content folge mir gerne auf Twitter, Mastodon oder LinkedIn.
Möchtest du den Newsletter wöchentlich per E-Mail erhalten?
Einfach hier abonnieren:
Moment, ist die Cloud nun etwa schlecht?
In den letzten Ausgaben habe ich ja ausführlich über den Cloud-Exit bei Basecamp berichtet. Der Cloud-Architect und AWS Serverless Hero Forrest Brazeal nimmt nun aus seiner Sicht Stellung zum mit viel Pauken und Trompeten angekündigten Cloud-Exit von 37signals und Basecamp.
Den ersten Abschnitt mit „Nostalgia as a Service“ würde ich mal überspringen, denn das hilft ja auch keinem weiter, Data Center von vor 20 Jahren mit heute zu vergleichen. Auch scheint er vergessen zu haben, dass Basecamp das DC und diverse Hardware Komponenten mietet und nicht selbst betreibt, ist also nicht so ganz vergleichbar.
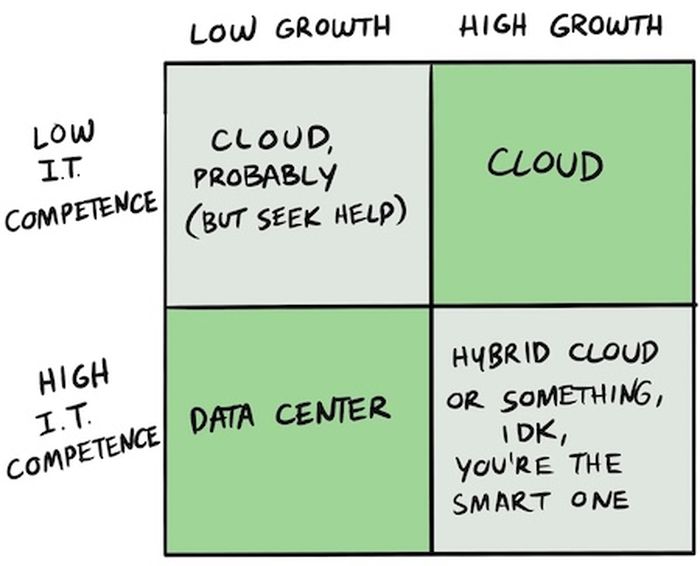
Nicht schlecht finde ich aber sein „Cloud or Data Center“ 2×2, daher habe ich das als Bild angehängt:
- Hohe IT Kompetenz, aber geringes Wachstumspotenzial – dann kann man im DC verbleiben – hier sei DHH und Basecamp angesiedelt
- Hohe IT Kompetenz und hohes Wachstumspotenzial– man möchte Hybrid Cloud oder etwas machen, das einem selber passt. Forrest nennt Snowflake als Beispiel dafür, ich bin mir nicht sicher, ob ihm bewusst ist, dass Snowflake 44 % seiner Umsätze direkt wieder als Cloud-Kosten ausgibt? Klar, wenn man an der Börse und mit Kundenumsätzen wächst, dann kann man diese Kosten vielleicht ignorieren – ob Snowflake das heute noch so machen kann?
- Geringe IT Kompetenz und hohes Wachstum – man möchte auf jeden Fall Cloud nutzen – man hat auch keine Zeit, das sauber zu bauen. Ja, das kann man sicherlich so tun und das machen auch viele. Man sollte halt seine Apps so bauen, dass sie portabel sind und nicht von Komponenten eines bestimmten Providers abhängen. Sonst ist man nicht besser dran als mit einem NetApp Filer, über die er sich im ersten Abschnitt etwas lustig gemacht hat.
- Geringer IT Kompetenz und geringes Wachstum – man sollte definitiv in die Cloud gehen, denn dann bekommt man Probleme und Standards abstrahiert, die man selber bald nicht mehr on-premise lösen kann. Das kann daran liegen, dass es dafür bald schlichtweg kein Personal oder keine Dienstleister mehr geben wird.
Und in einem Punkt hat Forrest absolut recht – die Cloud hat einen automatischen Feedback-Mechanismus eingebaut, der nahezu in Real-time funktioniert – die Rechnung. Diese ist nämlich Verursachergerecht und zeigt Kosten auf, die man on-premise gar nicht gesehen hat oder nicht entsprechend abrechnen konnte.
Stromausfall und große Störung bei Cloudflare
Seit letzten Donnerstag hatte Cloudflare diverse „Major Issues“ mit seinen Services. Los ging es am Donnerstag, 2.11.2023 um 11:43 Uhr UTC mit dem Verlust eines Teils der Cloudflare Control Plane und der Analytics Services. Die Analytics Services sind Teil der Log- und Analytics Plattform, die zentral Logs der Kunden aufzeichnet, Statistiken bereitstellt und teils eben auch als Werkzeug zur Mitigation genutzt wird.
Laut der sehr ausführlichen Statuspage gingen teilweise sogar Log Einträge verloren. Da Cloudflare und vor allem der CEO Matthew Prince gerne gegenüber anderen Services austeilt, hat er selbst das öffentliche Postmortem zum Ausfall verfasst – oder ist zumindest als alleiniger Autor genannt – vermutlich, dass er eben das Feuer abbekommt, das er sonst selbst anfeuert.
Was war passiert?
Cloudflare ist in Hillsboro, Oregon, in 3 voneinander unabhängigen Data Centern eingemietet. Die größte Einheit wird von Flexential betrieben, einem größeren Co-Location-Betreiber. Die 3 Data-Center sind in der Regel weit genug entfernt, um genug Redundanz zu einer Naturkatastrophe zu haben, aber nahe genug, um Active-Active Cluster zu betreiben. Die anderen Facilities werden nicht genannt, aber üblicherweise sind das schätzungsweise 20-40 km Distanz, damit die Optiken noch eine genügend geringe Latenz aufweisen.
Dieses Active-Active Cluster habe funktioniert, aber vor allem neuere Services und auch die Logging Plattform sind bisher nicht auf die Active-Active Infrastruktur migriert.
Das Problem ist jedenfalls in PDX-04 aufgetreten, einem Flexential Datacenter, wo Cloudflare laut eigenem Angaben selbst 10 % der Fläche gemietet hat und damit ein großer Kunde vor Ort ist.
Zum Stromausfall kam es dann durch eine Verkettung verschiedener Ereignisse. Bei einer der unabhängigen Stromleitungen in das Data Center kam es zu einem Ausfall. Der DC Betreiber hat dann die Generatoren angeworfen, um die fehlende externe Stromzufuhr abzufangen. In der Regel mache man das aber nicht, sondern ist entweder komplett offline und betreibt den gesamten Strombedarf mit den Generatoren, oder hängt eben komplett am Netz. In den USA scheint das laut dem Artikel häufiger zu passieren, dass der Netzbetreiber ein DC aus Kapazitätsgründen bittet, auf die Generatoren umzustellen.
Der Rest des Vorfalls ist bisher Spekulation aufseiten von Cloudflare, da noch keine Stellungnahme vom DC Betreiber vorliegt. Es gibt die Möglichkeit, dass der DC Betreiber dem Netzbetreiber aushilft und mit seinem Generatoren-Strom ins Netz zurück einspeist. Ob dies passiert ist, steht bisher nicht fest. Jedenfalls kam es zu einem „Ground fault“, einem Erdschluss, einer ungewollten Verbindung eines spannungführenden Leiters mit der Erde – aber halt bei 12.470 Volt. Jedenfalls sind in dessen Folge alle Generatoren des DCs aus Sicherheitsgründen heruntergefahren. Die Batterien, für 10 Minuten Überbrückung und eigentlich genau für solch einen Fall gedacht, gingen bereits nach 4 Minuten Offline – Flexential benötigte aber mehr als 10 Minuten, um die Generatoren wieder zu starten.
Diverse Services hatten Querabhängigkeiten zu Services, die in PDX04 exklusiv liefen – dies ist in vorherigen Tests nicht aufgefallen. Auch hier lässt Cloudflare ordentlich die Hose runter:
We had performed testing of our high availability cluster by taking offline each (and both) of the other two data center facilities entirely offline. And we had also tested taking the high availability portion of PDX-04 offline. However, we had never tested fully taking the entire PDX-04 facility offline. As a result, we had missed the importance of some of these dependencies on our data plane.
Um 12:48 UTC wollte Flexential den Strom wieder herstellen – und ja, dann vielen die Sicherungen raus. Ein DC Offline und wieder online zu bringen ist gar nicht so leicht. Cloudflare entschied sich um 13:40 UTC Zentrale Services in die Disaster Recovery Sites in Europa zu switchen. Das scheint aber ein manueller Prozess zu sein, dauerte daher bis 17:57 UTC an.
Um 22:48 UTC war der Strom bei Flexential wieder hergestellt, Matthew Prince schreibt allerdings im Artikel, dass er das Team erst mal ins Bett schicken wollte, da es für alle eine sehr stressige Situation war: „That decision delayed our full recovery, but I believe made it less likely that we’d compound this situation with additional mistakes.“ – Mutige, aber sicherlich sinnvolle Entscheidung.
Am Ende des Artikels listet er 8 größere Learnings und Verbesserungen, die Cloudflare in Zukunft einbauen möchte. Beeindruckende Transparenz, die Cloudflare hier abliefert – vor allem direkt nach dem Incident in dem hohen Detailgrad, das ist nicht üblich.
Post Mortem on Cloudflare Control Plane and Analytics Outage
Sponsored
8gears Container Registry
![]()
Container Images unterscheiden sich deutlich von anderen Artefakten hinsichtlich ihrer ständigen Verfügbarkeit.
Im Gegensatz zu NPM oder JAR Artefakte müssen Container Images für den operativen Betrieb der Anwendung durchgehend verfügbar sein. Auch sollte die Registry nicht auf den gleichen Clustern laufen wie die Anwendungen, um den MTTR (mean time to recovery) möglichst kurzzuhalten. Selbstverständlich sollte die Registry hochverfügbar ausgelegt werden, mit ansprechenden Datenbanken und Buckets.
Wenn es bloss jemanden gäbe, der das Ganze für einen übernehmen könnte?
Die 8gears Container Registry ist ein Harbor-basierte Container-Registry Service. Angeboten und betrieben von Harbor Projektbetreuern und Mitwirkenden.
Hochverfügbar in verschiedenen EU Datenzentren ganz in deiner Nähe.
Microsoft veröffentlicht Developer Plattform Radius
Microsoft hat eine neue cloud-native Application Platform mit dem Namen „Radius“ Open-Source veröffentlicht.
Bei „Radius“ klingelt es beim einen oder anderen vielleicht, denn das ist auch der Name des Radius Protokolls („Remote Authentication Dial-In User Service“), welches vor allem zur zentralen User-Verwaltung bei Hardware-Geräten wie Switches und Routern verwendet wird.
Jedenfalls ist Radius von Microsoft ein Tool, welches die Portabilität von Cloud-Native entwickelten Anwendungen über diverse Cloud-Provider sicherstellen soll. Dabei soll Radius den kompletten Lifecyle einer Anwendung unterstützen: Das initiale Erstellen eines Projekts (Define), das Deployment der Anwendung (deploy) und den gemeinsamen Betrieb (collaborate).
In der Dokumentation gibt es bereits ausführliche Tutorials, beispielsweise um eine neue Anwendung zu erstellen oder einen containerisierten E-Commerce Shop zu deployen.
Mit den Radius Recipes können Templates für Infrastruktur erstellt werden. Unterstützt wird hier aktuell Bicep und Terraform. Als Cloud-Provider werden aktuell AWS und Azure supported.
Einmal ein Rezept erstellt, so kann dies wiederverwendet werden. Wird „Redis“ als Service genutzt, so provisioniert Radius dann automatisch den entsprechenden managed Server je nach verwendetem Cloud Provider. Man könne damit dann wirklich Multi-Cloud machen, und trotzdem standardisiert 3rd Party Integrationen wie GitHub Actions oder eine Twilio Messaging API anbinden.
Azure CTO Mark Russinovich argumentiert den Nutzen von Raduis damit, dass Kubernetes zwar grundsätzlich ein Cloud-Enabler sei, dass ein typisches Application Team aber noch diverse andere Dinge benötigen würde, um erfolgreich in der Cloud zu agieren. Zudem helfe Radius auch beim Verständnis der Applikationen, beispielsweise durch den Application-Graph.
Interessant, in welche Richtung sich Open-Source bei Microsoft so entwickelt – wer hätte das vor 10 Jahren noch gedacht. Radius ist in der Apache 2.0 Lizenz auf GitHub verfügbar – aktuell in Version v0.26.9.
Microsoft Azure introduces Radius, an open-source development platform for multi-cloud computing
Okta Breach und Cloudflare Response
Im November hat der Identity Provider Okta einen weiteren Sicherheitsvorfall eingeräumt. Der Vorfall selbst war zwischen September und Oktober 2023 aufgetreten, und irgendwie hat Okta sich erst öffentlich dazu geäußert, nachdem Cloudflare in einem Blog-Eintrag darüber aufgeklärt hat.
Was war passiert?
Session Tokens von Okta Kunden (unter anderem Cloudflare, 1Password & BeyondTrust) wurden aus im Okta Support System angehängten HAR Files extrahiert und genutzt, um über die Tokens Zugriffe in die darunter liegenden Systeme zu erlangen. HAR Files sind JSON formatierte HTTP Archive Informationen, die die Klickstrecke eines Users im Browser komplett aufzeichnen – inklusive aller Inhalte. Laut diversen Tweets nutzt Okta „Salesforce Service Cloud“ als Support Tool Lösung.
Laut dem Eintrag im Cloudflare Blog informierte Cloudflare zuerst Okta und nicht andersherum.
Cloudflare lässt es sich dann auch nicht nehmen und listet „Recommendations for Okta“ und „Recommendations for Okta’s Customers“ auf.
Okta hat selbst einige „Remediation Tasks“ veröffentlicht – unter anderem blockt man in Zukunft auf allen Okta Laptops die Nutzung von privaten Google Profilen im Chrome. Das ist wohl ein kleiner Hinweis darauf, wie das Ganze ursprünglich passieren konnte. Schaut man sich die Timeline an, ist die Kritik an Okta berechtigt, denn man hat da in der Tat zu lange gewartet und Kunden nicht informiert. Laut Okta waren nur 1 % der Kunden, in Summe 134, von der Thematik betroffen. Die Anzahl der Kunden ist da jetzt auch nicht wenig aussagekräftig, finde ich – die Frage ist ja, wie viele Accounts die Kunden haben und wofür Okta da genutzt wird.
Ich habe mir dann auch schon gedacht, dass es sicherlich nicht lange dauern wird, bis Cloudflare eine eigene Identity Lösung bauen wird. Gergely Orosz erwartet auch genau das (siehe Nitter/Twitter Thread dazu).
Cloudflare hat nun jedenfalls 8 Tage nach dem Incident einen HAR file sanitizer veröffentlicht, mit dem man HAR Files von privaten Inhalten befreien kann. Das Tool kannst du direkt online verwenden oder auch via GitHub beziehen und selbst betreiben
How Cloudflare mitigated yet another Okta compromise
Twitter/X spart 60 % durch Cloud-Exit
Aus dem Hause Twitter gab es nun zur „Feier“ der Übernahme vor einem Jahr ein ausführliches Update aus dem Twitter Engineering Bereich.
Man habe den Tech-Stack optimiert, das „For You“ Ranking und den Algorithmus optimiert und dabei 90 % Lines of Code gestrichen und 50 % Compute Kosten eingespart. Kein Wunder, „For you“ ist ja auch vollkommen kaputt und unbrauchbar, ich jedenfalls bekomme da nichts Vernünftiges empfohlen, weshalb ich schon lange auf „Following“ auf default bin.
Spannend wird es im Bereich Cloud-Kosten – man habe das Sacramento Data-Center komplett abgebaut und die 5.200 Racks / 148.000 Server einem anderen Einsatzzweck zugeführt. Insgesamt spare man durch die Reduktion 100 Millionen Dollar pro Jahr, sowie 48 MW an Energiekosten. Verrückte zahlen, oder?
Gergely Orosz, Autor des Pragmatic Engineer Newsletters, ist auch erstmal beeindruckt. Er wurde dann aber auf einen Artikel bei techdirt hingewiesen, der Details zum Ablauf des DC Abbaus in Sacramento berichtet. Stimmt nur die Hälfte davon, ist das schon wirklich harter Tobak.
Laut dem Artikel habe ein Cousin von Elon während eines Fluges vorgeschlagen, die Server doch selber umzuziehen. Gesagt, getan – das Flugzeug wurde um geroutet, ein Mietwagen gemietet und ab ins DC nach Sacramento. Ursprünglich hatte eine für das DC verantwortliche Person erklärt, dass der Umzug Planung und Vorarbeit benötige. Vor Ort im DC hat Elon wohl selbst im Doppelboden den Strom eines Racks getrennt, um zu testen, welchen Einfluss eine solche Aktion auf Twitter haben könnte. Nachdem erst mal nichts passierte und Twitter weiter funktionierte, habe man kurzfristig einen Truck gemietet und die ersten 4 Racks abgebaut. Na ja, die die Geschichte weitergeht, könnt ihr im verlinkten Artikel lesen, das ist wirklich abenteuerlich.
Jedenfalls spart man nun ordentlich Kosten ein, in den Data-Centern selbst. Zudem habe man 60 % der Cloud-Kosten reduziert, da man viele Media / Blob Assets nach OnPremise umgezogen habe. Zusätzlich hat man auch Cloud Compute um 75 % reduziert. Bei den Assets bin ich mir nicht ganz sicher, wie das vorher gelaufen ist – aktuell werden Bilder über die https://pbs.twimg.com von Fastly ausgeliefert. Klar, die Original-Sourcen davon haben dann wohl vorher irgendwo in AWS S3 gelegen und nun halt irgendwo on-premise.
Basecamp/37Signals Gründer David Heinemeier Hansson rechnet im hier verlinkten Artikel vor, dass Twitter mit der Aktion um die 60 Millionen Dollar pro Jahr einsparen könnte. Die zuletzt bekannten AWS Kosten von Twitter haben um die 100 Millionen Dollar im Jahr betragen.
Das wäre schon beachtlich, reicht aber vermutlich nicht mal für die Zinsen aus, die Twitter aktuell bezahlt.
X celebrates 60% savings from cloud exit
Amazon EC2 M2 Mac Instanzen nun verfügbar
In der letzten Woche hat nicht nur Apple die M3 CPUs gelaunched, sondern auch AWS die Verfügbarkeit der EC2 M2 Instanzen bekannt gegeben.
Laut AWS haben die Instanzen 10 % mehr Leistung als die M1 Maschinen.
AWS nutzt dafür Mac Mini Computer mit 8 oder 10 Cores, 24 GB Memory und der 16 Core GPU.
M2 Instanzen haben in der Regel 1,5x soviel RAM und die 1,25-fache GPU Leistung im Vergleich zu den M1 Maschinen.
Für die Anbindung nutzt AWS ein eigens entwickeltes „Nitro System“ via Thunderbolt, in diesem Bild kannst du sehen, wie das in der Praxis ungefähr aussieht.
Aktuell sind die M2 Instanzen erstmal in US East (Nort Virginia und Ohia) und in US West (Oregon) verfügbar.
Announcing general availability of Amazon EC2 M2 Mac instances for macOS
Graylog 5.2 und 39 Millionen Dollar Finanzierungsrunde
Die populäre SIEM und Log Management Lösung Graylog ist in Version 5.2 erschienen. In 5.2 können IT Assets nun mit zusätzlichen Informationen angereichert werden, beispielsweise mit Informationen aus einer CMDB oder Asset Management Lösung.
Die Pipeline Rule UI würde deutlich vereinfacht und es gibt „ready-to-use“ sidecar Configs. Die neuen Features kannst du auch nächsten Donnerstag im Webinar zu 5.2 kennenlernen.
Viel wichtiger noch als das Release ist die Bekanntgabe einer neuen Finanzierungsrunde – nach einer 18 Millionen Dollar Series C im Jahr 2021 gab es nun eine Erweiterung dieser. Man hat 9 Millionen Dollar Equity und 30 Millionen per Kredit aufgenommen, insgesamt also 39 Millionen Dollar frisches Kapital.
Graylog wurde 2009 von Lennart Koopmann gegründet, damals noch bei Jimdo und Xing (oder hieß es da noch OpenBC?). Lennart hat den CEO Staffelstab 2020 an den neuen CEO Andy Grolnick übergeben, welcher inzwischen die Geschäfte leitet. Lennart selbst lebt noch in Houston, arbeitet aber bereits an etwas Neuem – dem Network Defense System nzyme.
Glückwunsch zur neuen Runde!
Log analysis and security firm Graylog raises $9M in equity, $30M in debt
Schmunzelecke
Der Twitter User @javilopen hat mithilfe von Midjourney, Dall-E und GPT-4 das Spiel Angry Birds in der Halloween-Edition „Angry Pumpkins“ entwickelt. Artwork, Code, etc. alles ist komplett mit AI Prompts und dem Hinweis auf Angry Birds gebaut worden. Den Link zum Twitter Thread findest du hier über Nitter.
Das Spiel kannst du hier ausprobieren.
Da Nitter ja letzte Woche nicht funktioniert, hier nochmals der Hinweis auf: „The floor is java“ – Link von Twitter via Nitter.
💡 Link Tipps aus der Open Source Welt
StackStorm – Event-Driven Troubleshooting und Incident Response
StackStorm ist eine event-basierte Lösung für die automatisierte Entstörung von Incidents. StackStorm (Hompeage Link) lauscht beispielsweise auf Monitoring Events und reagiert dann automatisch, wenn diese eintreten. Beispielsweise wenn eine Disk voll-läuft, so kann StackStorm verschiedene Dinge machen, um Speicherplatz bereitzustellen – Disk erweitern, Logfiles löschen/zippen – alles Dinge, die man sonst ggf. manuell gemacht hat, kann man mit StackStorm in einem playbook automatisiert ausführen.
Nicht umsonst bezeichnet sich StackStorm als „IFTTT for Ops„. In der Online-Exchange finden sich über 160 Integrationen, zu Cloud Providern, Monitoring Systemen, Logging Systemen oder auch eine generische Ansible Integration.
Natürlich gibt es Pakete für diverse Betriebssysteme und eine ausführliche Dokumentation inkl. Installationsanleitung. In diesem Video erhältst du eine erste Idee davon, wie StackStorm in der Praxis funktioniert.
https://github.com/StackStorm/st2
OpenSign – Weitere DocuSign Alternative
In Ausgabe #106 hatte ich bereits Documenso als Open-Source Docusign Alternative vorgestellt. Mit OpenSign gibt es nun eine weitere Lösung, die Self-hosted oder als SaaS Variante betrieben werden kann. Für die Installation wird eine MongoDB Datenbank benötigt, ansonsten läuft ein ReactJS Frontend mit NodeJS API.
Die digital unterschriebenen Dokumente können dann in einem S3 Bucket abgelegt werden.
Alle Funktionen findest du in der Übersicht bei GitHub. Das erste Release ist jetzt eine 1.0.1, es geht also direkt los mit einer stabilen Version.
https://github.com/OpenSignLabs/OpenSign
❓ Feedback & Newsletter Abo
Vielen Dank, dass du es bis hierhin geschafft hast!
Kommentiere gerne oder schicke mir Inhalte, die du passend findest.
Falls dir die Inhalte gefallen haben, kannst du mir gerne auf Twitter folgen.
Gerne kannst du mir ein Bier ausgeben oder mal auf meiner Wunschliste vorbeischauen – Danke!
Möchtest du den Newsletter wöchentlich per E-Mail erhalten?
Einfach hier abonnieren: