Willkommen zu allesnurgecloud.com – Ausgabe #138!
Tja, mit den Schaltjahr-Bugs war ich ein wenig zu voreilig, am Montag nach der Veröffentlichung des Newsletters hat mich dann selbst noch ein Fehler in der Schnittstelle meiner Bank getroffen. Deshalb gibt es diese Woche nochmals ein Update zu den Schaltjahr-Bugs.
Happy Bootstrapping Podcast
Vergangenen Donnerstag durfte ich bei den Campus Founders in Heilbronn über meine Learnings aus über 60 Podcastausgaben berichten. Ein tolles Event, bei dem ich mich mal wieder aus der Komfortzone herausbewegt habe und dabei wieder vieles gelernt habe.
In der aktuellen Folge 62 habe ich mit Jonas Emde von der Agentur mindtwo.de gesprochen – interessanterweise war mindtwo früher eher produktlastig unterwegs, konzentriert sich heute aber komplett auf das Agenturgeschäft. Vorherige Agenturen, die ich zu Gast hatte, waren eher andersherum unterwegs.
allesnurgecloud.com ist ein kuratierter Newsletter mit Inhalten aus der Open-Source, Cloud und IT-Welt.
Für weiteren Content folge mir gerne auf Twitter, Mastodon oder LinkedIn.
Möchtest du den Newsletter wöchentlich per E-Mail erhalten?
Einfach hier abonnieren:
Weiterhin Tech Layoffs und Fokus auf Profitabilität
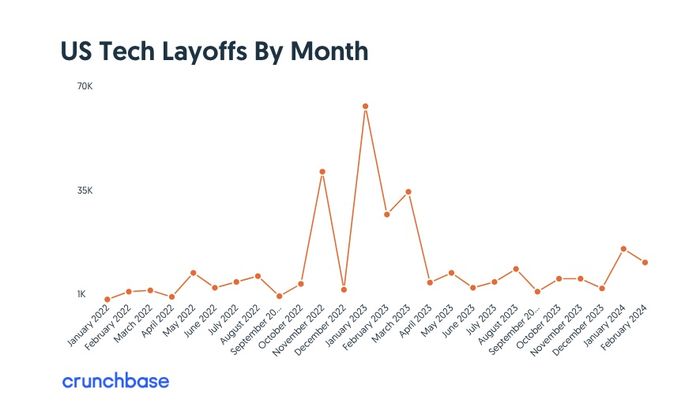
Während ich hier regelmäßig vom „First World Problem“ der „Return-to-Office“ Firmen berichte, setzen sich in den USA die Tech Layoffs unvermindert fort. Zwar nicht mehr so intensiv wie zum Jahreswechsel 2022/2023 (siehe Grafik) – aber dennoch spürbar:
- Bei Expedia trennt man sich von 1500 Angestellten oder 8 % der gesamten Workforce (Quelle: GeekWire).
- Der Spiele-Hersteller Electronic Arts trennt sich von 670 Angestellten ( 5 % der Angestellten, Quelle CNBC).
- Bei Sony Interactive sind 900 Mitarbeitende betroffen, ebenfalls 8 % der Angestellten (Quelle: The Verge).
- Die Hersteller der amerikanischen Dating-App Bumble trennen sich von 350 der Mitarbeitenden (30 % der Belegschaft, Quelle CNBC).
- Die beiden Auto-Hersteller Rivian und Fisker trennen sich ebenfalls von einem Teil der Belegschaft (15 % der Belegschaft bei Fisker, Quelle: TechCrunch).
Dies sind nur einige Beispiele – wie immer bekommst du im Layoff Tracker Layoffs.fyi einen guten Überblick.
Der verlinkte Artikel von Crunchbase beschreibt, dass sich viele Firmen in den letzten 2 Jahren hin zur Profitabilität umorientiert haben und somit etwas länger mit ihrem vorhandenen VC Geld durchhalten konnten (das ist im Artikel mit „extended Runway“ gemeint). Nun gehe aber vielen Firmen die Puste aus, eine Folgefinanzierung scheitert teilweise an zur hohen Bewertung vorheriger Runden oder einfach an der fehlenden Investitionsbereitschaft.
Anfang des Jahres konnten wir diesen Switch auch bei der deutschen Powerpoint Alternative Pitch beobachten – man entließ 80 von 120 Mitarbeitenden, CEO Christian Reber hing seinen Job an den Nagel und kündigte einen Rückkauf von Anteilen und eine Fokusänderung hin zur Profitabilität an. In diesem sehr empfehlenswerten Interview im Manager-Magazin (Paywall) spricht er über die anstrengenden Jahre, den Druck der VCs und über die „toxische Start-up Kultur“.
Ähnliches kann man jetzt bei PlanetScale, dem SaaS Anbieter für hoch-skalierbare MySQL Datenbanken in der Cloud, beobachten.
CEO Sam Lambert schreibt in einem aktuellen Blogartikel, dass „Reliabilty“ für ihn auch bedeute, dass die Firma profitabel sein müsse, damit sich die Kunden auf die langfristige Existenz verlassen können:
Reliability isn’t just an uptime percentage on your status page. It means your business is self-sustaining.
Every unprofitable company has a date in the future where it could disappear. With an ever changing world and economy, this is a situation fraught with risk.
We’ve chosen to build a company that can last forever. This is why I have made the decision to prioritize profitability for PlanetScale.
In dem Zuge trenne man sich von einem Teil der Belegschaft und stelle den günstigen Hobby-Plan demnächst ein. Aktuell ist der Plan schon nicht mehr zu buchen, Datenbanken, die bis zum 8. April nicht auf das höhere „Scaler Pro“ Level aktualisiert werden, werden in einen „Schlafmodus“ versetzt (siehe FAQ dazu).
Die 4 Wochen finde ich doch recht kurzfristig, da gerade Start-up Projekte und Side-Hustles häufig solche kleinen Pläne verwenden, damit sie überhaupt ans Laufen kommen. Das zeigt mal wieder, wie gefährlich Abhängigkeiten zu solchen Firmen sein können.
Nicht falsch verstehen, ich verstehe den Switch , die kleinen Pläne sind halt immer durch „Premium“ Kunden subventioniert, und bei Sparmaßnahmen werden sie eben als Erstes eingestellt.
Tech Layoffs Stay High As Extended Runways Reach Their Limit
Bugs im Schaltjahr 2024 (Part Two)
Tja, da war ich in der letzten Woche wohl doch zu voreilig mit den ausgebliebenen Schaltjahr Bugs:
Meine Geschäftsbank (Postbank/Fyrst) hatte übers Wochenende beschlossen, dass auf den 29.02.2024 der 30.02.2024 folgt.
Somit konnte mein Buchhaltungsprogramm (Lexoffice) keine Buchungen über die Schnittstelle abrufen, da es tatsächlich Buchungen mit dem 30.02. als Zeitstempel gab.
Leider hat die Postbank die Kunden hierüber gar nicht informiert und so fand sich nur bei Lexoffice folgender Hinweis:
Derzeit werden über die Bankschnittstelle Umsätze mit Datum 30.02.2024 geliefert, was zu einem Fehler führt.
Der Sachverhalt befindet sich in Prüfung. Sobald es Neuigkeiten gibt, aktualisieren wir diesen Hinweis.
Mittlerweile ist der Hinweis verschwunden, die Postbank hat auch im Nachgang nicht dazu informiert.
Im unten verlinkten Artikel bei „The Pragmatic Engineer“ Gergely Orosz finden sich dann doch einige „Leap Day Bugs“, die dieses Jahr aufgetreten sind.
In Schweden konnte in der Supermarkt-Kette ICA keine Kartenzahlung mehr durchgeführt werden – Schuld war der 29. Februar. Ob die auch die Systeme der Postbank nutzen?
In Kolumbien druckte die größte Airline des Landes, Avianca, den 1. März auf die Boarding-Pässe anstatt dem 29. Februar – immerhin reagiert die Airline schnell und konnte den Passagieren auf elektronischem Weg eine Alternative mitteilen (Ticket neu herunterladen, App benutzen).
Und auch in Neuseeland konnte man bei für mehr als 10 Stunden nicht mehr mit Karte bei diversen Tankstellen bezahlen, wie der „New Zeland Herald“ berichtet.
Spieler des Electronic Arts Games „EA Sorts World Rally Championship“ (released im November 2023) konnten am 29. Februar nicht spielen – es stürzte einfach mit einem Crash ab. Als Übergangslösung solle man den Systemzeitstempel auf den 1. März setzen und jetzt habe ich starke 90er Vibes.
Gergely warnt in seinem Blog-Artikel vor weiteren Fehlern zum Ende des Jahres, da manche IT-Systeme annehmen, dass jedes Jahr 365 Tage habe – und dieses Jahr hat ja mit 366 Tagen einen Tag mehr. Mal schauen, wer den 1. Januar 2025 dann einen Tag früher feiert.
Im Blogartikel listet er zudem einige Falschannahmen auf, die häufig beim elektronischen Umgang mit Zeiten und Daten begangen werden.
Sponsored
8gears Container Registry
![]()
Container Images unterscheiden sich deutlich von anderen Artefakten hinsichtlich ihrer ständigen Verfügbarkeit.
Im Gegensatz zu NPM oder JAR Artefakte müssen Container Images für den operativen Betrieb der Anwendung durchgehend verfügbar sein. Auch sollte die Registry nicht auf den gleichen Clustern laufen wie die Anwendungen, um den MTTR (mean time to recovery) möglichst kurzzuhalten. Selbstverständlich sollte die Registry hochverfügbar ausgelegt werden, mit ansprechenden Datenbanken und Buckets.
Wenn es bloß jemanden gäbe, der das Ganze für einen übernehmen könnte?
Die 8gears Container Registry ist ein Harbor-basierte Container-Registry Service. Angeboten und betrieben von Harbor Projektbetreuern und Mitwirkenden.
Hochverfügbar in verschiedenen EU Datenzentren ganz in deiner Nähe.
Wo ist sie hin, die Developer Productivity?
Stephan Schmidt ist ein erfahrener CTO, der mittlerweile einen empfehlenswerten Newsletter schreibt und andere CTOs auch coacht.
In einem aktuellen Artikel beschäftigt er sich mit der Produktivität von Entwicklern und fragt, wo diese denn hin verschwunden ist. Eigentlich müsste diese durch diverse Verbesserungen doch besser sein?
Wir haben schließlich
- Cloud und Automatisierung-Cloud, Terraform, Ansible und andere Tools sorgen für eine einfach verfügbare Infrastruktur – häufig mit kostenlosem Einstieg
- CI/CD Prozesse sind einfacher und dank GitHub und GitLab für alle verfügbar
- schnelle Hardware (SSDs und Multicore sorgen dafür, dass man mal kurz was bauen und ausprobieren kann)
- bessere und schnellere Programmiersprachen, oder die Sprachen von damals sind nun besser und einfacher (Frameworks, etc.)
- und eine besser vernetze Community – Egal ob Meetups, Slack und Discord – früher fand das alles in Usergroups statt und diese waren nicht so einfach zugänglich.
In den letzten Jahrzehnten erlebt. Stephan schreibt dazu:
There is a case of mysterious loss of developer productivity.
Developer productivity should have risen, but it didn’t, and I don’t know why. I have talked to many people about this, some agree and some disagree, everyone has a theory, but there is no consensus.
Stephan meint, dass man mit den ganzen Tools und Techniken, ja eigentlich denken könnte, dass Entwickler heute 10x mal so viel pro Zeiteinheit liefern – dem sei aber nicht so.
Seine Vermutung verteilt sich auf viele Themen:
- Meetings-Entwickler würden 10-20 % ihrer Arbeitszeit in Scrum Meetings verbringen
- Entwickler benötigen zu viele verschiedene Tools, um produktiv zu arbeiten
- Früher war die „IT“ zu anderen Einheiten klar getrennt – IT spielt heute überall rein, in Marketing, HR, Vertrieb, etc. – Features sind komplexer und verzahnter mit anderen Systemen
- Cloud sei zwar einfach, aber auch komplex – häufig weiß man nicht, was man aus dem Zoo der Angebote nun verwenden soll und evaluiert erst mal.
- SPAs nennt er ebenfalls – das kann ich im Freundeskreis so auch nachvollziehen – man benötigt APIs, validiert zweimal, etc. – da gibt es für viele Fragestellungen eigentlich einfachere Lösungen.
Ich sehe mittlerweile auch viel „overengineering“, wo es nicht nötig ist. Ein kleines Projekt mit MongoDB, PostgreSQL, Redis und Elasticsearch – wo man doch auch 80 % der Themen in MySQL oder PostgreSQL abfeuern könnte. Interessanterweise hat Stephan hierfür auch einen Artikel – „just use Postgres for everything„.
In Summe glaube ich daher auch, dass wir ein Stück verlernt haben, einfach nur das Ergebnis schnell zu produzieren, mit Technologie, mit der man sich auskennt. Häufig nutzt man Projekte ja auch, um neue Technologien dann auszuprobieren und dann dauert ein Projekt deutlich länger als geplant.
The Mysterious Case of Lost Developer Productivity
Praxis-Tipps: Angst vor dem „Bereitschaftsdienst“ nehmen
In verlinkten Artikel im PagerDuty Blog gibt es diverse Vorschläge, wie man angehenden On-Call Engineers die „Angst vor dem Bereitschaftsdienst“ nehmen kann.
Bei PagerDuty gibt bereits diverse Guides zum Thema, beispielsweise „Full Service Ownsership“ und „Best Practices for On Call Teams„, deshalb hat man nun Leute aus der Praxis nach echten Tipps aus der Praxis gefragt.
John Miller findet „Playbooks“ gut, die war nicht alle Antworten enthalten müssen, aber zumindest mal eine Auflistung der Services des Teams, deren Deployment Prozess, Links zu Monitoring-systemen und eine Historie aller bisherigen Incidents enthalten. Gerade den letzten Punkt finde ich interessant, hier entsteht ja ein gutes Wissen und Fehler kommen häufig wieder oder wiederholen sich exakt nochmal, da macht es Sinn, nicht die gleiche Analyse nochmal zu fahren.
Einige andere Antworten finde ich eher schwach – ein „Time and experience solve this fear to some extent“ – das hilft einem Neueinsteiger nicht. Hier halte ich es für gut, wenn man einem Einsteiger einen „On-Call Shadow“ bereitstellt – jemanden, den er zur Not anrufen kann, der selbst erfahren ist und sich mit den zu betreuenden Systemen auskennt.
Gut finde ich wiederum, daran zu denken, dass alle irgendwann das erste mal „On-Call“ waren. Das deckt sich mit den gerade erwähnten On-Call Shadow:
All who are on-call, once had a first time on-call If you are working in a team, you will not be alone in the air, and somebody will shadow you
Einen Tipp, den ich gerne gebe – der fehlt in der Liste. Bei größeren Systemen macht es total Sinn, eine explizite Person für die „Kommunikation“ abzustellen – in den üblichen Rollenbeschreibungen findet man diese Person als „Incident Commander“, „Incident Manager“ oder auch „Business Impact Manager“.
Atlassian beschreibt die Rolle des „Incident Manager“ folgendermaßen:
This person’s priority is to guide an incident to its resolution as quickly and completely as possible, managing the resources, plan, and communication involved in that resolution.
Die Personen, die direkt an der Entstörung arbeiten, sollten nicht auch noch mit Stakeholder Kommunikation oder dem Erstellen von Status-Page Einträgen abgelenkt werden.
Gerade für Neueinsteiger, aber auch für alle anderen ist es wichtig, sich auf die Entstörung zu konzentrieren.
Practitioners Share How They Remove the Fear of On-Call
GitLab stärkt FluxCD Projekt
Vor 4 Wochen hatte ich über das Ende von Weaveworks (Firma hinter FluxCD) und der geplatzten Finanzierungsrunde berichtet.
Auf LinkedIn hat Weaveworks CEO Alexis Richardson nun ein Update zur Zukunft von FluxCD geteilt. Die meisten der Mitarbeitenden haben mittlerweile eine neue Anstellung gefunden. Die Firma Weaveworks wandle sich mehr in eine Community, die die Projekte weiterhin verwalten möchte. Die Maintainer des Projekts verteilen sich nun auf mehrere Firmen, und das Projekt hänge nicht mehr am Tropf einer Firma – das findet er dann doch gut.
Im Speziellen bedankt er sich bei GitLab, die in einem Blog-Post announced haben, dass sie das Projekt weiterhin supporten werden. GitLab hatte FluxCD Anfang 2023 in seiner eigenen Lösung integriert. Nun stärkt man diese Verbindung und möchte in Zukunft eine tragende Rolle für das Projekt übernehmen, selbst Maintainer stellen und die Integration weiter verbessern.
The continued support of FluxCD at GitLab
Bechtle und Nextcloud mit Partnerschaft
Das IT-Systemhaus Bechtle und der Collaboration Suite Anbieter Nextcloud haben eine Zusammenarbeit angekündigt.
Ziel der Zusammenarbeit soll sein, dass Nextcloud für den öffentlichen Sektor leichter zugänglich ist, Zeiten für Ausschreibungen gekürzt und Einlaufs- und Beschaffungsprozesse effizienter ablaufen können.
Laut Angaben von Nextcloud (Pressestatement in Deutsch) ist die Nextcloud Software mittlerweile auf bis zu 50 Millionen User skalierbar und wird bereits in Frankreich, Schweden oder auch von der EU-Kommission eingesetzt.
Die „digital souveräne Kollaborationslösung“ von Nextcloud soll in Zusammenarbeit mit Bechtle im RZ des ITZ Bund, im Bechtle eigenen RZ oder bei einem „anderen Cloudanbieter“ gehostet werden.
Bechtle and Nextcloud offer digitally sovereign collaboration services for the public sector
Cloudflare veröffentlich Pingora Open-Source
Zum Ende Februar hatte Cloudflare die Open-Source Veröffentlichung seines Netzwerkframeworks Pingora fertiggestellt.
Das Projekt ist in Rust geschrieben und bildet die Basis für viele Cloudflare Services. Mit „40 Millionen Requests pro Sekunde“ sei das Framework nun „battle-tested“ und reif für die Veröffentlichung – auf GitHub ist das Projekt nun also komplett transparent einsehbar.
Das Projekt enthält diverse Libraries, kommt mit einer API und unterstützt beispielsweise „Hot-Reload“ ohne Neustart. Im Blog Artikel wird gezeigt, wie einfach man damit einen einfachen Loadbalancer bauen kann.
Das Memorysafety Projekt hat daraufhin erste Designdokumente für einen neuen Reverse Proxy auf Basis von Pingora veröffentlicht. Der neue Reverse Proxy River soll in Zukunft eine moderne Alternative zu gängigen Reverseproxies werden.
Open sourcing Pingora: our Rust framework for building programmable network services
Civo Cloud kauft kubefirst Projekt
Der englische Cloud-Anbieter Civo Cloud kauft die GitOps Plattform „kubefirst“ vom Inhaber Kubeshop.
Finanzielle Details zum Deal sind bisher nicht bekannt, da kann man also nur spekulieren.
Kubefirst konnte man bisher mit ein paar Clicks im Marktplatz der Civo Cloud bekommen, in Zukunft soll das Ganze noch besser verzahnt werden.
John Diez, der CEO fin Kubefirst sagt zur Akquisition:
This partnership marks the beginning of an exciting chapter, allowing us to leverage Civo’s resources while continuing to serve our community and maintain our foundational principles. We remain dedicated to driving innovation and excellence in the Kubernetes ecosystem.
Man möchte jedoch auch nach der Akquise für die Community da sein, die Software weiterhin Open-Source anbieten und auch in Zukunft Cloud-agnostische Lösungen anbieten.
Civo Expands cloud-native offering with Kubefirst acquisition
Schmunzelecke
„Company accidentally increased dev productivity 3x by laying off 20% of middle management“ – ok, der Artikel ist Satire bei „The Olognion“, aber ich musste etwas schmunzeln.
💡 Link Tipps aus der Open Source Welt
Ente – End-to-end encrypted Google Phots und Authy Alternative
Bei Ente gibt es neben dem coolen Namen zwei Open-Source-Tools, die mir aufgefallen sind:
- Ente Photos – eine Alternative zu Google Photos und Apple Photos, die du selbst hosten kannst
- Ente Auth – eine kostenlose 2FA Alternative zum Authentikator Authy
Finanziert wird das Angebot über SaaS Pläne für die Foto-Lösung, die je nach Storage Größe kosten – hier geht das ab 2,99€ für 50GB los, der größte Plan ist der Pro Plan mit 2TB für 19,99€ im Monat.
Ente selbst ist in Typescript geschrieben und kann auch selbst gehosted werden. Der Server, Museum, kann per docker-compose selbst betrieben werden. Im „Dockerfile“ wird eine PostgreSQL und ein Minio als S3 Speicher benötigt – das kann man natürlich auch außerhalb selbst betreiben, wie man möchte.
Puter: Open Source Browser Desktop Environment
Puter ist ein Open Source Browser Desktop Environment – also eine Remote Desktop Service.
Du kannst Puter selbst hosten, Software darin installieren oder auch einfach nur als Dropbox/Google Drive Alternative verwenden.
Lokal ausprobieren kannst du das einfach mit Docker/Compose:
git clone https://github.com/HeyPuter/puter
cd puter
docker compose upEs gibt aber eine schnelle Online-Demo, die dir zeigt, was Puter so kann und was noch nicht.
https://github.com/HeyPuter/puter
❓ Feedback & Newsletter Abo
Vielen Dank, dass du es bis hierhin geschafft hast!
Kommentiere gerne oder schicke mir Inhalte, die du passend findest.
Falls dir die Inhalte gefallen haben, kannst du mir gerne auf Twitter folgen.
Gerne kannst du mir ein Bier ausgeben oder mal auf meiner Wunschliste vorbeischauen – Danke!
Möchtest du den Newsletter wöchentlich per E-Mail erhalten?
Einfach hier abonnieren: